Scapple: a great little brainstorming gem
There are plenty of programs available for jotting down thoughts and ideas, like note-taking software Evernote or mind-mapping application XMind. I have tried and used many over the years. But there’s one small app that hardly ever gets mentioned and has been more useful to me than any other program. It’s called Scapple.
Note: I’m talking about the Mac version, I have not tested on Windows.
Scapple is simple yet powerful
There are two reasons why Scapple does its job so well:
- simplicity: it offers just enough functionality to not distract me from my task.
- flexibility: it does not restrict my workflow as other programs.
Let me explain:
Simplicity
When I tried Scapple for the first time, I could immediately jot down my thoughts and had the feeling of “flow”. The default settings like font size, colors, shapes are working well. The appearance of the app seems quite basic but that’s why it actually works for me.
Yet, under the hood, it accomplishes a lot.
For example, it is possible to drag any kind of file into a Scapple document. It can be other Scapple files, PDFs, hyperlinks or images.
I’m using images a lot. Icons to illustrate thoughts or screenshots when I need to demonstrate something that can be better done with an image than with words.
Flexibility
Scapple does not start with one central thought from which everything else has to evolve. Instead, I can start writing anywhere and connect what I want.
I find this so much better than the mind map concept. I like mind maps when I want to brainstorm quickly without thinking too much. But this is also possible in Scapple: just hit CMD+ENTER to “stack” notes below each other. If I want to branch out, I just hit CTRL + CMD + arrow to make a new connection to a new note.
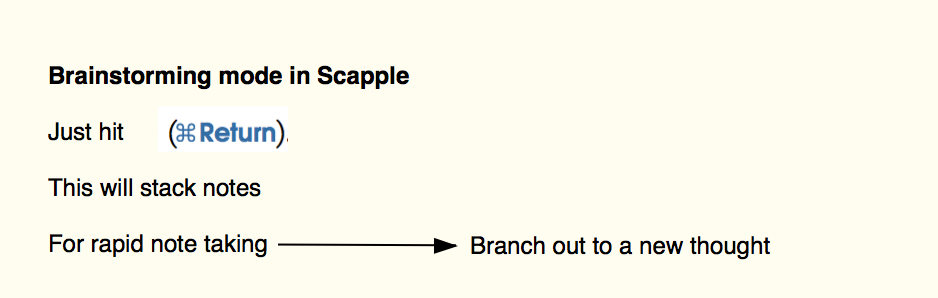
Then, by playing with colors, borders, images, I can easily cluster my thoughts. That’s the main advantage for me. In a mind mapping application, I may add notes but that is not the same. And in a typical note-taking tool like Evernote, I can’t move single thoughts around as I can in Scapple.
Basically, Scapple comes closest to a real notebook while having all the advantages of being software.
What is missing
Then there are a few “nice to have” features:
-
No convenient way to split large files into smaller ones. Once files become too big there is no easy way to organize them. It would be great if I could create a new Scapple file from selected some notes and then link to this file. It is possible to duplicate Scapple files and then delete the notes that are not needed but it’s cumbersome.
-
No library. Scapple files are isolated documents. I use DEVONthink to organize my files, but it would help to be able to organize files in folders and search across the whole library
-
Custom formatting. It is possible to create custom formats, but not across files
-
No icons. I can easily drag images into a note (see above) so this one is not that important, still, it would nice to have some default icons
Give it a try
Head over to the creators of Scapple and try the free trial: Scapple
Combining Scapple with other software
In a next post, I’m going to introduce you to the “other half” of my software setup: DevonThink. These two together comprise my main tools I do most of my work with. They work great together.
Thanks for reading
I hope this post was helpful for you. If you have comments, questions or found a bug please let me know, either in the comments below or contact me directly.
Using Spring with Scala (Spring I/O 2016)
Summary: Demonstrating the steps that are necessary to use Spring with Scala by translating Spring.io’s guides from Java to Scala.
This is the content of my talk I gave at the Spring I/O conference in Barcelona (19.&20.05.2016). Slides can be found here.
- But why?
- Examples
- Summary
- Scala SDK is getting better at dealing with Java
- Conclusion
- Thanks for reading
Scala is becoming a popular choice when developing for the JVM. However, developers with a Spring/Java background might be reluctant to give up all of their familiar tools and frameworks.
In this post I’d like to demonstrate how to introduce Scala into an existing Spring/Java environment.
But why?
Using Spring with Scala feels a bit like this:

It seems I’m trying to sneak in Scala into the harmonic marriage of Spring with Java. A valid question therefore is: why should someone want to do this?
I think there are good reasons.
Why Scala?
I could also ask: why learn a new programming language? There are probably two reasons:
- For fun: learning a new programming language makes me a better developer
- For profit: your boss might want to use it, the job market has an increasing number of Scala projects etc.
Scala was built for functional programming from ground up, where for Java it’s been added on top of it. And that shows up in code, many times solutions can be expressed more concisely in Scala.
Why Spring + Scala?
Possible reasons why this might be a good idea:
- You come from a Java/Spring background and think it sufficient in the beginning to learn a new language. Why drop also all the tools that you know and are efficient in (I for example absolutely love Spring Boot, I don’t want to give it up).
- New languages come always with new frameworks and tools. Those are that: new and unproven. There is some risk involved using them. Spring has been around for a very long time and is proven and comes with support.
- Probably the most common reason: you and your team want to gradually introduce Scala into your existing Java/Spring project. This is without problems possible.
Examples
In order to demonstrate how we can use Scala with Spring I went to the guide section of Spring.io1, selected a few of the guides and translated them into Scala.
The source code of the examples can be found as usual on Github2.
The Spring.io guides have the advantage of being short, yet showcasing distinct features of Spring.
First example: serving websites using Spring MVC
The Spring MVC example consists basically of four files:
.
├── build.gradle
└── src
└── main
├── java
│ └── hello
│ ├── Application.java
│ └── GreetingController.java
└── resources
└── templates
└── greeting.html
We have our build file (Gradle), the template, the Spring main application and a controller (we don’t have a model in this simple example).
Making Gradle work with Scala
In order to make Gradle work with Scala, we just need to add the Scala plugin and add the dependency to Scala.
apply plugin: 'scala'
apply plugin: 'application'
mainClassName = "hello.Application"
dependencies {
compile 'org.scala-lang:scala-library:2.11.1'
}I’ve also added the application plugin so that I can execute the examples using gradle run but that is optional.
That’s all that is necessary to build & run the examples.
Application class
The Java application class is a typical Spring Boot application (Application.java):
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}This becomes following in Scala (Application.scala):
@SpringBootApplication
class Application {
}
object Application extends App {
SpringApplication.run(classOf[Application], args:_*)
}We don’t have static methods in Scala, so we add an object to our main class. We can use Java/Spring annotations like @SpringBootApplication in Scala the same way as in Java (one exception see below).
We only need to pass our arguments as args:_* (basically a compiler hint).
That’s all there is to do. This is true for the rest of the examples.
Template
Of course, no changes need here, just to demonstrate how this example works, the template (template.html) looks like this:
<!DOCTYPE HTML>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Getting Started: Serving Web Content</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
</head>
<body>
<p th:text="'Hello, ' + ${name} + '!'" />
</body>
</html>We pass a name parameter to the template.
Controller
The Java side is a typical MVC controller (GreetingController.java):
@Controller
public class GreetingController {
@RequestMapping("/greeting")
public String greeting(@RequestParam(value="name", required=false, defaultValue="World") String name, Model model) {
model.addAttribute("name", name);
return "greeting";
}
}In Scala, we only need to handle the @RequestMapping annotation differently. Instead of passing just a String, we need to wrap it into an Array("/greeting") (file GreetingController.scala):
@Controller
class GreetingController {
@RequestMapping(Array("/greeting"))
def greeting(@RequestParam(value="name", required=false, defaultValue="World") name: String, model: Model) : String = {
model.addAttribute("name", name)
"greeting"
}
}That’s it. We can now run the project and ping the endpoint:
$ gradle run
...
2016-05-06 16:05:52.644 INFO 1297 --- [ restartedMain] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 8080 (http)
2016-05-06 16:05:52.650 INFO 1297 --- [ restartedMain] scala.App$class : Started App.class in 5.117 seconds (JVM running for 5.753)
$ curl http://localhost:8080/greeting?name=SpringIO
<!DOCTYPE HTML>
<html>
<head>
<title>Getting Started: Serving Web Content</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
</head>
<body>
<p>Hello, SpringIO!</p>
</body>
</html>
Example consuming a REST service
In this example, we access a sample rest service to retrieve a random quote.
complete-java$ tree .
.
├── build.gradle
├── src
│ └── main
│ └── java
│ └── hello
│ ├── Application.java
│ ├── Quote.java
│ └── Value.java
Beans in Scala
Simple POJOs are shorter with less boilerplate in Scala, however, they don’t follow the bean standard with getter/setter. In order to make this work, we need to annotate fields of a bean with Scala’s @BeanProperty annotation (Value.scala):
@JsonIgnoreProperties(ignoreUnknown = true)
class Value {
@BeanProperty
var id: Long = _
@BeanProperty
var quote: String = _
override def toString : String = "Value{id=" + id +", quote=" + quote +"}"Asynchronous consumption
The original guide uses a synchronous RestTemplate to access the webservice. That translates almost 1:1 in Scala. To make things a bit more interesting, let’s use an asynchronous example.
The Java application class (Application.java):
RestTemplate restTemplate = new RestTemplate();
Quote quote = restTemplate.getForObject("http://gturnquist-quoters.cfapps.io/api/random", Quote.class);
log.info(quote.toString());
// Async version
AsyncRestTemplate asyncTemplate = new AsyncRestTemplate();
final ListenableFuture<ResponseEntity<Quote>> quoteFuture = asyncTemplate.getForEntity("http://gturnquist-quoters.cfapps.io/api/random", Quote.class);
quoteFuture.addCallback(
success -> log.info("async: " + quote),
failure -> log.error("Async error", failure));The example uses the AsynchRestTemplate. Calling the endpoint returns a future that we can attach two callbacks to, one for the success case and one for a failure. addCallback is Java 8 ready, meaning we can use Java 8 Lambdas.
Java 8 Lambdas look strikingly similar to Scala function literals
Java: (Integer a, Integer b) -> a + b
Scala: (a:Int, b:Int) => a + b
However, putting Scala functions into the Spring callback method does not work. We have to fall back to ugly anonymous classes:
quoteFuture.addCallback(new ListenableFutureCallback[ResponseEntity[Quote]]() {
override def onSuccess(entity : ResponseEntity[Quote]) : Unit =
log.info("async: " + entity.getBody.toString)
override def onFailure(t : Throwable) : Unit =
log.error("Async error", t)
})This is going to change with Scala 2.12. See below.
Example: providing a REST API
├── build.gradle
├── complete-java.iml
├── complete-java.ipr
├── complete-java.iws
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
├── gradlew.bat
└── src
└── main
└── java
└── hello
├── Application.java
├── Person.java
└── PersonRepository.java
In Spring Data Rest most work resolves around implementing repositories.
The Java side is straight forward (PersonRepository.java):
@RepositoryRestResource(collectionResourceRel = "people", path = "people")
public interface PersonRepository extends PagingAndSortingRepository<Person, Long> {
List<Person> findByLastName(@Param("name") String name);
}That translates almost 1:1 in Scala (PersonRepository.scala):
@RepositoryRestResource(collectionResourceRel = "people", path = "people")
trait PersonRepository extends PagingAndSortingRepository[Person, Long] {
def findByLastName(@Param("name") name: String): List[Person]
}However, running this creates an error:
PersonRepository.scala:8: type arguments [hello.Person,Long] do not conform to trait PagingAndSortingRepository's type parameter bounds [T,ID <: java.io.Serializable] trait PersonRepository extends PagingAndSortingRepository[Person, Long] {
which translates is due to: Scala Long != Java Long. We need to make sure to pass the Java base type to the Java interface import java.lang.Long (or use the full package name).
Final example: JDBC
In this example, we access a relational database using JdbcTemplates. We create a table, insert some data and execute a query to check the results.
Java side
jdbcTemplate.execute("DROP TABLE customers IF EXISTS");
jdbcTemplate.execute("CREATE TABLE customers(" +
"id SERIAL, first_name VARCHAR(255), last_name VARCHAR(255))");
// Split up the array of whole names into an array of first/last names
List<Object[]> splitUpNames = Arrays.asList("John Woo", "Jeff Dean", "Josh Bloch", "Josh Long").stream()
.map(name -> name.split(" "))
.collect(Collectors.toList());
// Use a Java 8 stream to print out each tuple of the list
splitUpNames.forEach(name -> log.info(String.format("Inserting customer record for %s %s", name[0], name[1])));
// Uses JdbcTemplate's batchUpdate operation to bulk load data
jdbcTemplate.batchUpdate("INSERT INTO customers(first_name, last_name) VALUES (?,?)", splitUpNames);
log.info("Querying for customer records where first_name = 'Josh':");
jdbcTemplate.query(
"SELECT id, first_name, last_name FROM customers WHERE first_name = ?", new Object[] { "Josh" },
(rs, rowNum) -> new Customer(rs.getLong("id"), rs.getString("first_name"), rs.getString("last_name"))
).forEach(customer -> log.info(customer.toString()));The steps in Scala:
Create a collection of names in Scala
Dealing with Java, we can’t use Scala’s default immutable collections. Instead, we need to fall back to mutable package in Scala.
import scala.collection.mutable.ListBuffer
val splitUpNames = ListBuffer("John Woo", "Jeff Dean", "Josh Bloch", "Josh Long“).map(_.split(" "))
splitUpNames.foreach(name => log.info("Inserting customer record for %s %s".format(name(0), name(1))))
passing a collection to Java
The signature of batchUpdate method is this: public int[] batchUpdate(String sql, List<Object[]> batchArgs)
We need to pass a List<Object[]> collection. This requires type casting:
- Java
Object<=> ScalaAnyRef - Java Array
[]<=> ScalaArray - Java (mutable) List <=> Scala
mutable.Buffer
We do the casting here:
jdbcTemplate.batchUpdate(
"INSERT INTO customers(first_name, last_name) VALUES (?,?)“,
splitUpNames
.asInstanceOf[mutable.Buffer[Array[AnyRef]])Now, splitUpNames.instanceOf[...] is still a Scala collection that we can’t pass to Java. For this, Scala provides JavaTransformations.asJava. The complete code becomes:
import collection.JavaConverters._
jdbcTemplate.batchUpdate(
"INSERT INTO customers(first_name, last_name) VALUES (?,?)“,
splitUpNames
.asInstanceOf[mutable.Buffer[Array[AnyRef]].asJava)Querying the db: receiving a collection from Java
In the final step, we want to accomplish this in Scala:
jdbcTemplate.query().foreach(...)Here, we have to other direction and need to call asScala on the collection that is returned from Java.
The complete implementation:
jdbcTemplate.query(
"SELECT id, first_name, last_name FROM customers WHERE first_name = ?",
Array("Josh").asInstanceOf[Array[AnyRef]],
// no Java 8 Lambda support in Scala < 2.12
new RowMapper[Customer]{
override def mapRow(rs: ResultSet, rowNum: Int): Customer = new Customer(rs.getLong("id"), rs.getString("first_name"), rs.getString("last_name"))
}).asScala.foreach((customer:Customer) => log.info(customer.toString))Summary

Those are the steps I had to do in order to make my selection of guides work in Scala:
| What | Step | Effort required |
|---|---|---|
| Make Gradle work with Scala | add scala plugin & dependency |
easy |
| Application class | split into class & object, pass args with args:_* |
easy |
| Use Spring annotations | need to add Array(STRING) |
easy |
| Create beans in Scala | Use @BeanProperty annotation |
easy |
| Implement Java/Spring interface | Import java base types | slightly annoying |
| Using Java collections in Scala and vice versa | Transform collections using JavaTransformations asJava and asScala |
slightly annoying |
| Pass collections from Java to Scala and vice versa | Casting required, eg Object to AnyRef | annoying |
| Pass collections from Java to Scala and vice versa | We have to use mutable collections in Scala | annoying |
| Using Scala functions as Java Lambdas | Not possible for Scala < 2.12 | annoying / not a problem anymore |
Scala SDK is getting better at dealing with Java
One important point to remember: the Scala SDK is getting better at working with Java 8. Scala 2.12 has Lambda support and that makes working with Spring a lot better in Scala.
That brings me to another point: what about using additional frameworks that ease working with Spring? For example, there has been a now defunct Spring-Scala project3. I think there is no need for a framework like that. I prefer to deal in a consistent way with my Java dependencies and rather bet on the Scala SDK to further improve.
Conclusion
If you are wondering why I have only talked about how to use Java from Scala and not more about using Spring from Scala, you are right. And that’s the good news because it means:
It works. Spring is just another Java framework that I can use from Scala.
Drawbacks of using Spring instead of a pure Scala framework:
- I may not always be able to write most idiomatic Scala code
- Transforming & casting can get tiresome
Advantages:
- I can keep my productivity (Spring Boot, yay!)
- I can use a well-proven and supported framework
Thanks for reading
I hope this post was helpful for you. If you have comments, questions or found a bug please let me know, either in the comments below or contact me directly.
Resources
Java versus Go: a performance comparison
Summary: Comparing the performance of Go with Java when filtering the lines of a large log file using regular expressions.
- The task
- Setup
- Regex filter
- Implementation
- Go implementation
- Java implementation
- Conclusion
- Thanks for reading
- Resources
Together with a friend, I recently pondered an idea to build a new kind of time-series database to process log files. The question we discussed was: what programming language would be most suitable for the task?
We are both experienced Java developers. But my friend was convinced that Go, with it light-weight threads and C roots, would outperform Java. I don’t know Go well and wanted to see if I can confirm this using a simple test.
In this post I’d like to find out if Go really is that faster than Java (for that particular case).
The task
The scenario is following: we want to process a large (>1GB) log file by applying a regular expression on each line, and if a match was found, print the line out to the console.
Setup
We are using Go version 1.5. The test code is available in github1. Each test needs to compiled separately.
Creating the sample log file
First we need to have a log file to process. We create it ourselves using Go. The lines should have following format:
2015-11-12 15:02:28.93508032 +0100 CET -- log entry #0
Numbering each line has the advantage that we get an idea of progress of the processing.
On my machine, a log file with 20.000.000 lines creates a file with a size of around 1.24 GB. We create a log file like this:
func main() {
log.Println("Creating log file: " + logFile)
fo, err := os.Create(logFile)
now := time.Now()
for i:=0; i < numberOfLines; i++ {
date := now.Add(time.Duration(i) * time.Second)
_, err = fo.WriteString(fmt.Sprintf("%v -- %v\n", date, fmt.Sprintf("log entry #%v", i)))
if i % 100000 == 0 {
log.Printf("... created %v lines", i)
}
}
log.Printf("Done writing %v lines", logFile)
}Create the logfile using:
$ go build create-log-file.go
$ ./create-log-file
Regex filter
The filter we are using is this: .*\#[15][15]1110+$, i.e entries that start with 1 or 5, followed by 1 or 5, followed by 111 and ending with at least one 0. Quite arbitrary, but this filter spreads the matches relatively evenly across concurrent processes. There are 10 lines that match in our log sample.
Implementation
There are basically two costly operations:
- reading each line from the log file
- applying a regular expression on each line.
This is a task that should gain from being executed in parallel. If we had 20 million cores, each core could process one line (however, the feeding of the cores would still be happening sequentially).
Go implementation
Note: GOMAXPROCS
Before version 1.5 of Go, it was necessary to set the number of logical processors in Go when using parallel execution. Like this:
cpu := runtime.NumCPU()
log.Printf("Num cpu: %v\n", cpu)
runtime.GOMAXPROCS(cpu)
This is not necessary anymore 2, so in my tests I won’t tweak this setting (more concretely, I won’t write about this, in fact, I did tweak it and it made no difference whatsoever. Try it yourself if that interests you).
Looping through the log file
We start with measuring the time it takes to loop through the log file. Go offers basically two ways to do that: using bufio.Scanner and bufio.Reader.
Note: In the code examples I’m only showing the relevant parts for brevity (e.g I omit error handling). Please see the github repo for the complete implementation.
func main() {
start := time.Now()
log.Printf("Started: %v", start)
inputFile, err := os.Open("log-sample.txt")
scanner := bufio.NewScanner(inputFile)
i := 0
for scanner.Scan() {
line := scanner.Bytes()
i++
if line == nil {} // just to avoid compilation error
}
fmt.Printf("Count: %v\nElapsed time: %v\n", i, time.Since(start))
}$ go build scanner-performance.go
$ ./scanner-performance
2015/11/20 10:21:53 Started: 2015-11-20 10:21:53.717315327 +0100 CET
Count: 20000000
Elapsed time: 2.266481235s
That looks promising. We process 20 million lines in 2.2 seconds. Let’s see how this compares to bufio.Reader:
func main() {
start := time.Now()
log.Printf("Started: %v", start)
inputFile, err := os.Open("log-sample.txt")
defer inputFile.Close()
reader := bufio.NewReader(inputFile)
i := 0
for _, _, err := reader.ReadLine(); err==nil;
_, _, err = reader.ReadLine(){
i++;
}
fmt.Printf("Count: %v\nElapsed time: %v\n", i, time.Since(start))
}The result:
$ go build reader-performance.go
$ ./reader-performance
2015/11/20 10:24:54 Started: 2015-11-20 10:24:54.322864572 +0100 CET
Count: 20000000
Elapsed time: 1.843919688s
That’s even faster so let’s use Reader.
Regular expression in Go
We are going to use the regexp module of go:
var regex = regexp.MustCompile(".*#[15][15]1110+$")
...
if regex.Match(string) ....Sequential solution
The sequential solution is straightforward: open the log file and filter each line using a regex.
var regex = regexp.MustCompile(".*#[15][15]1110+$")
func main() {
count := 0
start := time.Now()
log.Printf("Started: %v", start)
inputFile, err := os.Open(logfile.LogFile)
defer inputFile.Close()
reader := bufio.NewReader(inputFile)
for line, _, err := reader.ReadLine(); err==nil;
line, _, err = reader.ReadLine(){
if regex.Match(line) {
fmt.Printf("Match: %v\n", string(line))
}
}
fmt.Printf("Elapsed time: %v\n", time.Since(start))
}Run with:
$ go build sequential.go
$ ./sequential
The result
2015/11/20 10:29:40 Started: 2015-11-20 10:29:40.944923413 +0100 CET
Match: 2015-11-19 21:14:40.002737283 +0100 CET -- log entry #111110
Match: 2015-11-20 08:21:20.002737283 +0100 CET -- log entry #151110
Match: 2015-11-24 12:21:20.002737283 +0100 CET -- log entry #511110
Match: 2015-11-24 23:28:00.002737283 +0100 CET -- log entry #551110
Match: 2015-12-01 11:01:10.002737283 +0100 CET -- log entry #1111100
Match: 2015-12-06 02:07:50.002737283 +0100 CET -- log entry #1511100
Match: 2016-01-16 18:07:50.002737283 +0100 CET -- log entry #5111100
Match: 2016-01-21 09:14:30.002737283 +0100 CET -- log entry #5511100
Match: 2016-03-26 04:46:10.002737283 +0100 CET -- log entry #11111000
Match: 2016-05-11 12:52:50.002737283 +0200 CEST -- log entry #15111000
Elapsed time: 1m38.747270878s
Around one and a half minutes. That is rather disappointing.
After a little bit of research and reading about Go’s regex implementation, we may improve the performance of the regex. But strictly speaking, that should not be allowed in this test, as we want to offer a system that can deal with all sorts of regex (we’d need to implement some internal optimization then).
If we change the regex from .*#[15][15]1110+$ to ^[^#]*#[15][15]1110+$, we get following result:
2015/11/20 10:34:27 Started: 2015-11-20 10:34:27.920836865 +0100 CET
...
Elapsed time: 1m2.590272369s
Indeed, this regex performs better. Still, one minute is not very satisfying, we are aiming for something much faster.
Parallel processing
How can we try to get more concurrency into our program? The best would be if we could just split the log file into even chunks and process those in parallel. But as we need to process complete lines (of arbitrary length), I don’t see an immediate solution for that.
We still could split the files in a pre-processing step. Or we could fill an array with lines and process that in parallel.
But all this is rather unusual. The “classical” way to process a task like this concurrently is to insert a queue into the process. The inventors of Go have given us already everything we need to that, namely, goroutines and channels.
Let’s try this then: the main process goes through the log file and puts each line into a queue. A set of workers pick up the lines from the queue and apply the regular expression. We are only going to use an unbuffered channel, as this guarantees message delivery.
const numberWorkers = 4
var waitGroup sync.WaitGroup
var regex = regexp.MustCompile("^[^#]*#[15][15]1110+$")
func main() {
start := time.Now()
log.Printf("Started: %v", start)
inputFile, err := os.Open("log-sample.txt")
defer inputFile.Close()
waitGroup.Add(numberWorkers)
queue := make(chan []byte)
for gr := 1; gr <= numberWorkers; gr++ {
go worker(queue, gr)
}
reader := bufio.NewReader(inputFile)
for line, _, err := reader.ReadLine(); err==nil;
line, _, err = reader.ReadLine(){
queue <- line
}
close(queue)
waitGroup.Wait()
fmt.Printf("Elapsed time: %v\n", time.Since(start))
}
func worker(queue chan []byte, id int) {
defer waitGroup.Done()
for {
line, ok := <-queue
if !ok {
fmt.Printf("Worker: %d : Shutting Down\n", id)
return
}
if regex.Match(line) {
fmt.Printf("[%v] Match: %v\n", id, string(line))
}
}
}Execute:
$ go build parallel.go
$ ./parallel
The result using 4 workers:
2015/11/20 10:47:21 Started: 2015-11-20 10:47:21.150202228 +0100 CET
[4] Match: 2015-11-19 21:14:40.002737283 +0100 CET -- log entry #111110
[2] Match: 2015-11-20 08:21:20.002737283 +0100 CET -- log entry #151110
[1] Match: 2015-11-24 12:21:20.002737283 +0100 CET -- log entry #511110
[2] Match: 2015-11-24 23:28:00.002737283 +0100 CET -- log entry #551110
[1] Match: 2015-12-01 11:01:10.002737283 +0100 CET -- log entry #1111100
[4] Match: 2015-12-06 02:07:50.002737283 +0100 CET -- log entry #1511100
[2] Match: 2016-01-16 18:07:50.002737283 +0100 CET -- log entry #5111100
[1] Match: 2016-01-21 09:14:30.002737283 +0100 CET -- log entry #5511100
[1] Match: 2016-03-26 04:46:10.002737283 +0100 CET -- log entry #11111000
[2] Match: 2016-05-11 12:52:50.002737283 +0200 CEST -- log entry #15111000
Worker: 4 : Shutting Down
Worker: 1 : Shutting Down
Worker: 3 : Shutting Down
Worker: 2 : Shutting Down
Elapsed time: 54.745756999s
Yes we have improved the result, around 54 seconds, not much but at least something.
Do we get a better result with more workers? Let’s double them: 8 and then 16.
8 workers:
2015/11/20 10:54:30 Started: 2015-11-20 10:54:30.267149314 +0100 CET
[5] Match: 2015-11-19 21:14:40.002737283 +0100 CET -- log entry #111110
[1] Match: 2015-11-20 08:21:20.002737283 +0100 CET -- log entry #151110
[1] Match: 2015-11-24 12:21:20.002737283 +0100 CET -- log entry #511110
[5] Match: 2015-11-24 23:28:00.002737283 +0100 CET -- log entry #551110
[3] Match: 2015-12-01 11:01:10.002737283 +0100 CET -- log entry #1111100
[1] Match: 2015-12-06 02:07:50.002737283 +0100 CET -- log entry #1511100
[1] Match: 2016-01-16 18:07:50.002737283 +0100 CET -- log entry #5111100
[7] Match: 2016-01-21 09:14:30.002737283 +0100 CET -- log entry #5511100
[7] Match: 2016-03-26 04:46:10.002737283 +0100 CET -- log entry #11111000
[1] Match: 2016-05-11 12:52:50.002737283 +0200 CEST -- log entry #15111000
Worker: 2 : Shutting Down
Worker: 5 : Shutting Down
Worker: 8 : Shutting Down
Worker: 1 : Shutting Down
Worker: 3 : Shutting Down
Worker: 7 : Shutting Down
Worker: 4 : Shutting Down
Worker: 6 : Shutting Down
Elapsed time: 37.484420982s
Wow, huge gain. That comes a little bit by surprise as the number of logical processors on my machine is 4, and I would have thought that anything greater than that would just cause overhead. But is shows that Go’s promise, that creating goroutines is cheap, seems to be true.
16 workers:
Elapsed time: 33.005427284s
Still better. Lets increase further:
32 workers:
Elapsed time: 31.268409369s
64 workers:
Elapsed time: 31.390695598s
128 workers:
Elapsed time: 31.204039411s
It looks like we are not gaining much by increasing the number of workers beyond 32.
So here we go: the best we could do in Go (using language default elements and no further tweaking) is around 30 seconds to process 20 million lines with a regular expression. Let’s see how Java performs.
Java implementation
The loop
We are going to use standard Java BufferedReader to process the log file:
class BufferedReaderPerformance
{
public static void main(String[] args)
{
Instant start = Instant.now();
System.out.println("Started: " + start);
try (InputStream in = Files.newInputStream(Paths.get("../logprocessing-performance-go/log-sample.txt"));
BufferedReader reader = new BufferedReader(new InputStreamReader(in)))
{
String line;
int i = 0;
while ((line = reader.readLine()) != null)
{
i++;
}
System.out.println(i);
}
catch (IOException ex)
{
System.err.println(ex);
}
Instant end = Instant.now();
System.out.println(Duration.between(start, end));
}
}The result:
Started: 2015-11-20T10:10:40.377Z
20000000
PT5.079S
5 seconds. Not as fast as Go, Java is already falling behind.
Sequential
Using the java.util.regex package, the implementation is straight forward:
class Sequential
{
public static final Pattern pattern = Pattern.compile("^[^#]*#[15][15]1110+$");
public static void main(String[] args)
{
Instant start = Instant.now();
System.out.println("Started: " + start);
try (InputStream in = Files.newInputStream(Paths.get("../logprocessing-performance-go/log-sample.txt"));
BufferedReader reader = new BufferedReader(new InputStreamReader(in)))
{
String line;
while ((line = reader.readLine()) != null)
{
final Matcher matcher = pattern.matcher(line);
if (matcher.matches())
{
System.out.print(String.format("Match: %s\n", line));
}
}
}
catch (IOException ex)
{
System.err.println(ex);
}
Instant end = Instant.now();
System.out.println(Duration.between(start, end));
}
}The result:
Started: 2015-11-20T10:13:10.038Z
Match: 2015-11-19 21:14:40.002737283 +0100 CET -- log entry #111110
Match: 2015-11-20 08:21:20.002737283 +0100 CET -- log entry #151110
Match: 2015-11-24 12:21:20.002737283 +0100 CET -- log entry #511110
Match: 2015-11-24 23:28:00.002737283 +0100 CET -- log entry #551110
Match: 2015-12-01 11:01:10.002737283 +0100 CET -- log entry #1111100
Match: 2015-12-06 02:07:50.002737283 +0100 CET -- log entry #1511100
Match: 2016-01-16 18:07:50.002737283 +0100 CET -- log entry #5111100
Match: 2016-01-21 09:14:30.002737283 +0100 CET -- log entry #5511100
Match: 2016-03-26 04:46:10.002737283 +0100 CET -- log entry #11111000
Match: 2016-05-11 12:52:50.002737283 +0200 CEST -- log entry #15111000
PT18.13S
Holy shmokes! 18 seconds. That comes with a big surprise. Even though the looping takes more time, the Java result clearly outperforms Go.
In this particular case, regular expression processing is done much faster in Java than Go.
Concurrent solution
Let’s see if we can further improve the result. In Java, we don’t have immediate language constructs like Channels to build a queue. But we can quite easily create a Producer/Consumer pattern.
We are going to use java.util.concurrent.ExecutorService to manage thread creation and java.util.concurrent.ArrayBlockingQueue as the queue implementation.
class Parallel
{
public static final Pattern pattern = Pattern.compile("^[^#]*#[15][15]1110+$");
static final int numberOfWorkers = 4;
static ExecutorService executor = Executors.newFixedThreadPool(numberOfWorkers);
static final ArrayBlockingQueue<String> queue = new ArrayBlockingQueue<String>(512);
public static void main(String[] args)
{
Instant start = Instant.now();
System.out.println("Started: " + start);
try (
InputStream in = Files.newInputStream(Paths.get("../logprocessing-performance-go/log-sample.txt"));
BufferedReader reader = new BufferedReader(new InputStreamReader(in))
)
{
// start workers
for (int i = 0; i < numberOfWorkers; i++)
{
Worker worker = new Worker(queue, i);
executor.submit(worker);
}
String line;
while ((line = reader.readLine()) != null)
{
queue.put(line);
}
executor.shutdown();
}
catch (Exception ex)
{
System.err.println(ex);
}
Instant end = Instant.now();
System.out.println(Duration.between(start, end));
}
static class Worker implements Runnable
{
private final BlockingQueue<String> queue;
private final int id;
public Worker(BlockingQueue<String> q, int id)
{
queue = q;
this.id = id;
}
public void run()
{
try
{
while (!Thread.currentThread().isInterrupted())
{
String line = queue.take();
final Matcher matcher = pattern.matcher(line);
if (matcher.matches())
{
System.out.print(String.format("[%s] Match: %s\n", id, line));
}
}
}
catch (InterruptedException ex)
{
}
}
}
}2 workers:
Started: 2015-11-20T10:16:50.941Z
[0] Match: 2015-11-19 21:14:40.002737283 +0100 CET -- log entry #111110
[1] Match: 2015-11-20 08:21:20.002737283 +0100 CET -- log entry #151110
[1] Match: 2015-11-24 12:21:20.002737283 +0100 CET -- log entry #511110
[0] Match: 2015-11-24 23:28:00.002737283 +0100 CET -- log entry #551110
[0] Match: 2015-12-01 11:01:10.002737283 +0100 CET -- log entry #1111100
[0] Match: 2015-12-06 02:07:50.002737283 +0100 CET -- log entry #1511100
[1] Match: 2016-01-16 18:07:50.002737283 +0100 CET -- log entry #5111100
[0] Match: 2016-01-21 09:14:30.002737283 +0100 CET -- log entry #5511100
[0] Match: 2016-03-26 04:46:10.002737283 +0100 CET -- log entry #11111000
[1] Match: 2016-05-11 12:52:50.002737283 +0200 CEST -- log entry #15111000
Done
PT18.278S
4 workers:
PT22.691S
8 workers:
PT26.831S
We don’t gain anything by introducing concurrency in the (already fast) sequential implementation. Threads are expensive in Java.
Conclusion
Java wins. What is nice in Go is the ability to introduce concurrency at little or no cost. It helped to double the performance. On the Java side, the overhead of creating (expensive) threads did not give any performance boost. However, processing regular expressions (the way we have been using them in this test) performs much better in Java.
Recap of the results
Testing machine: MacBook Pro, Intel Core i5, 2.4GHz, 2 cores, 8GB Ram
Input file: plain-text log file with 20.000.000 lines (1.24GB)
Go
| Algorithm | Settings | Execution time |
|---|---|---|
| Looping with counter | n/a | 1.8s |
| Sequential processing | n/a | 1m2s |
| Parallel unbuffered channel | number of goroutines: 4 | 54s |
| Parallel unbuffered channel | number of goroutines: 8 | 37s |
| Parallel unbuffered channel | number of goroutines: 16 | 33s |
| Parallel unbuffered channel | number of goroutines: 32 | 31s |
| Parallel unbuffered channel | number of goroutines: 64 | 31s |
| Parallel unbuffered channel | number of goroutines: 128 | 31s |
Java
| Algorithm | Settings | Execution time |
|---|---|---|
| Looping with counter | n/a | 5s |
| Sequential processing | n/a | 18s |
| Parallel BlockingQueue | number of threads: 2 | 18s |
| Parallel BlockingQueue | number of threads: 4 | 22s |
| Parallel BlockingQueue | number of threads: 8 | 26s |
Can you improve those results? If so let me know :)
Thanks for reading
I hope this post was helpful for you. If you have comments, questions or found a bug please let me know, either in the comments below or contact me directly.
Resources
How to have an elephant brain
Summary: Introducing a local search engine for Markdown files, available on Github. And how note-taking got me a new brain.
One colleague once told me I had an elephant brain because I’d remember all the configuration details of a rather complex app we developed that time. The truth is actually the opposite. Memorising has always been a weak side of mine. I tried to improve my remembering skills by dabbling with mnemonics and reading “Moonwalking with Einstein” but nothing really helped. In fact, I sometimes feel that something in me wants to oppose the need to remember mere facts that could be easily looked up.
However, around ten years ago, I did something else. I was working on 2-3 projects at the same time and noticed that I tend to look up the same kind of information over and over again. I got annoyed by this. Why couldn’t I remember something I found out a few days ago? So I tried something new: whenever I had to search for some fact or made a decision I knew I might forget later on, I took a note of it. Over the years I made a habit out of this and I think I’d qualify for being an excessive note-taker.
I write down everything I think I’d might forget or what might become a “remembering” challenge later. There are obvious things like “how do git hooks work”, “how do I create Intellij files using Gradle?”, the Stackoverflow kind of knowledge chunks. But also when developing software, for example, things I consider not clear and that may become a problem later, I document those. Speed is important. Nowadays, before thinking “should I take a note of this…” I probably have it already written down somewhere.
The advantages of note-taking
The obvious advantage is I’m able to remember much faster a fact. I have it stored somewhere and “all” I need is to find it (more about that later). But there are other advantages:
- It helps to digest the material. Not really news, every student knows that, but worth repeating. Learning something and then writing it down, preferably in one’s own words, helps a lot digesting and integrating new knowledge.
- Taking notes makes one more productive. Instead of merely consuming knowledge I actually create something.
- It is writing practice. Writing is a habit (as any author can confirm) and even though it might not be sufficient to write your next novel, writing down little things every day do help increasing one’s writing fluency.
- You become the guy with the deja-vus in your team (because you took a note somewhere and problems start to sound familiar “haven’t we talked about this two months ago…”)
Plain text + preferred editor as the best note taking software
Over the years I have tried quite a lot of note taking applications. One crash of an application that used a proprietary binary format, however, taught me the value of plain text. That plus the invention of Markdown never let me look back to anything else. There are now plenty of nice Markdown editors available that make creating notes a snap. I have a folder on my disk (backed-up constantly) that contains all my notes (in some hierarchy) and that’s it.
Creating new notes is not the problem. Finding them is, once you have a certain amount of data.
Finding notes is the challenge
Plain text has another huge advantage: it enables processing the files on my own. Most of the time it is possible with “on board” search of any OS to find what you are looking for. But it can be done better. Why not take advantage of the fact that the files are written in Markdown? For example, how about giving words a boost that are emphasized? Or those that are in the headlines?
Another habit I started some time ago was that the first line of my files (usually the h1 headline #) is a list of keywords that makes it easier to find the note later. It has become a fluent process for me to write down my notes that way. How about a search engine that treats the first line of a Markdown as a list of tags and that allows me to search for those?
Show HN: markdown search, tagging included
It is actually quite easy (weekend effort) to build a local search engine that does all this.

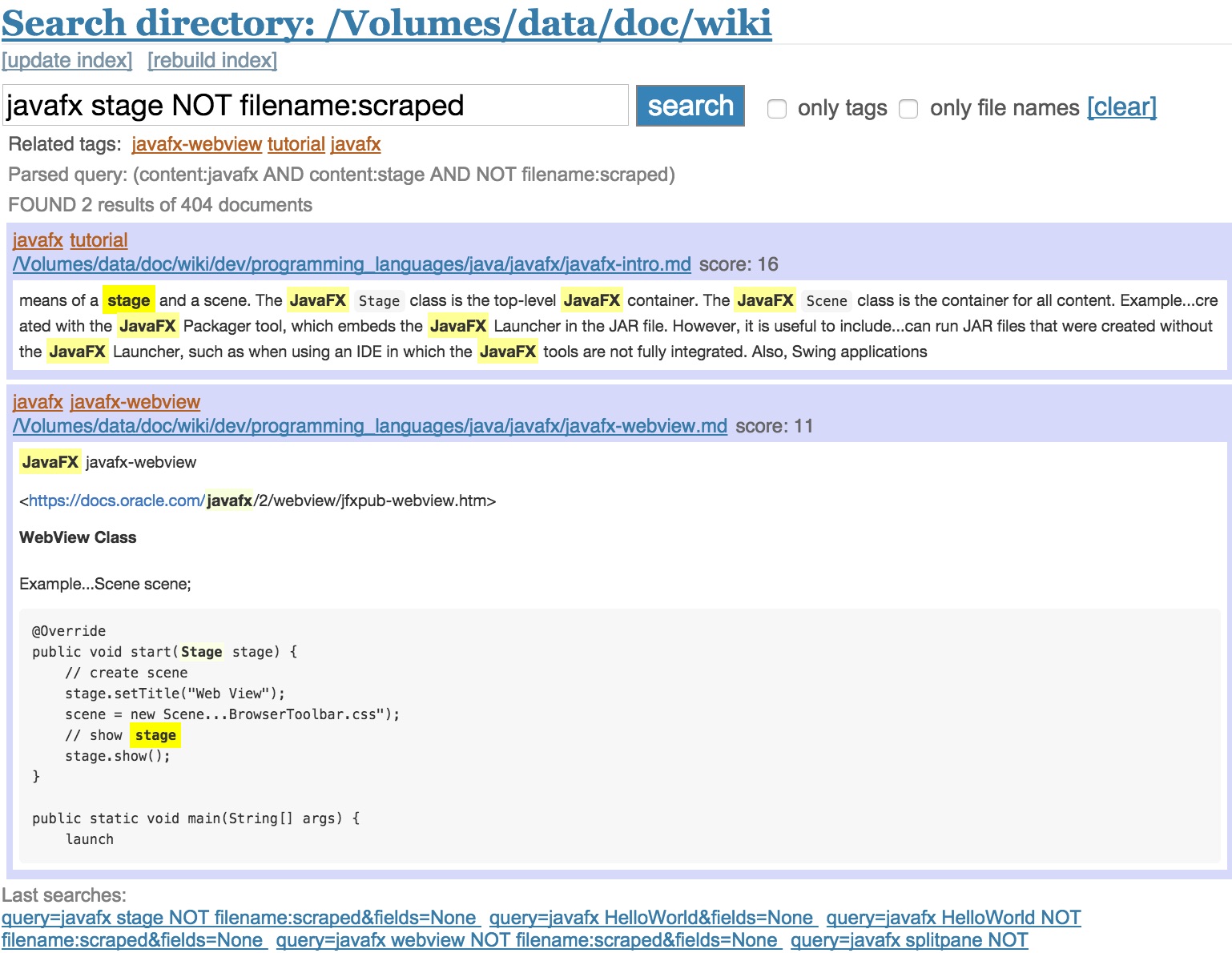
Built using Flask, Whoosh and Mistune.
The project (with documentation) is on Github1 if you like to try it out for yourself.
Clojure hands-on tutorial for beginners: building a spell-checker
Summary: A Clojure tutorial building a spell checker. A step-by-step guide that invites the reader to participate. Aimed at Clojure beginners, gives just enough knowledge about the language to start developing.
- Requirements
- Why a spell checker?
- How does a spell checker work?
- Implementation in Clojure
- Improvements
- Thanks for reading
- Resources
I’d like to experiment with a slightly different type of tutorial. Programming is primarily learned by doing. I’m going to describe in a step-by-step manner how to build a spell checker, but instead of just showing the solutions, questions and exercises are offered that build up to a working example.
The solutions are hidden and can be revealed by clicking on the ... click here to reveal solution ... text. That way, the reader is invited to come up with an own solution first before seeing the tutorial’s solution. I also try to not overwhelm the reader by giving just enough knowledge about Clojure to get started and answer the questions.
I’d appreciate any feedback, especially from Clojure beginners, to let me know if you found that approach useful or not.
Requirements
Leiningen1 installed. Please follow the instructions on their website how to download and install it on your system.
A little bit of Clojure knowledge would be good. I recommend working through some of the Clojure tutorial2. It’s quite dense, but I’d say spending an hour or so is sufficient for this tutorial.
Know how to start a Clojure REPL (well, just type lein repl) and how it works. More information in the Clojure tutorial3.
Some programming knowledge. If you are an absolute beginner and don’t know the difference between a map and a list then this might be too much to start with.
Preparations before we start
Create a new project
Let’s first create our project. As we use Leiningen, this is going to be a snap.
Start-up a console and type
$lein new app clojure-spellchecker
This creates all necessary files. Change into clojure-spellchecker. During this tutorial we are going to edit only two files:
src/clojure_spellchecker/core.cljis our main Clojure file. All our coding happens hereproject.cljwill only require one change later on
We’ll also need a list of words. A google search for “list of English words” gives us some choices, for example this long (109582) list of English words. Download and put it into the resources folder. Then rename it to wordsEn.txt.
Loading core.clj into REPL
We can test our code directly in REPL. Whenever it says: “try in REPL” do following steps:
- In the
clojure-spellcheckerrun:lein repl - Load the program by entering
(load-file "src/clojure_spellchecker/core.clj"). Use cursor up/down keys for going through the command history. Every new change we do requires to load our file again (there’s another way to accomplish that but for now, this is good enough)
Executing our app
The project is already executable, type in lein run and you will be greeted with the beloved “Hello World” message. Later we are using this to run our program outside the repl.
If you don’t want to follow step-by-step the final project can be found in Github.
That’s all that is needed to get started!
Why a spell checker?
I chose to use a spell checker as an example because of several advantages:
- a (somewhat) working prototype can be developed very easily in a few lines of code.
- it is a practical application that everyone has seen before.
- the very basic solution offers a lot of room for improvement and can be extended into an almost infinitely complex piece of software.
How does a spell checker work?
I won’t risk too much if I assume that you have already seen a spell-checker work. Open your text editor of choice and look for “spell check” or just start typing a (miss-spelled) word into Google and you’ll receive a “did you mean xy” answer.
How can we implement a basic working solution? Our spell checker has to do two things:
- Check whether the typed-in word is correct.
- If not correct, offer a possible correction.
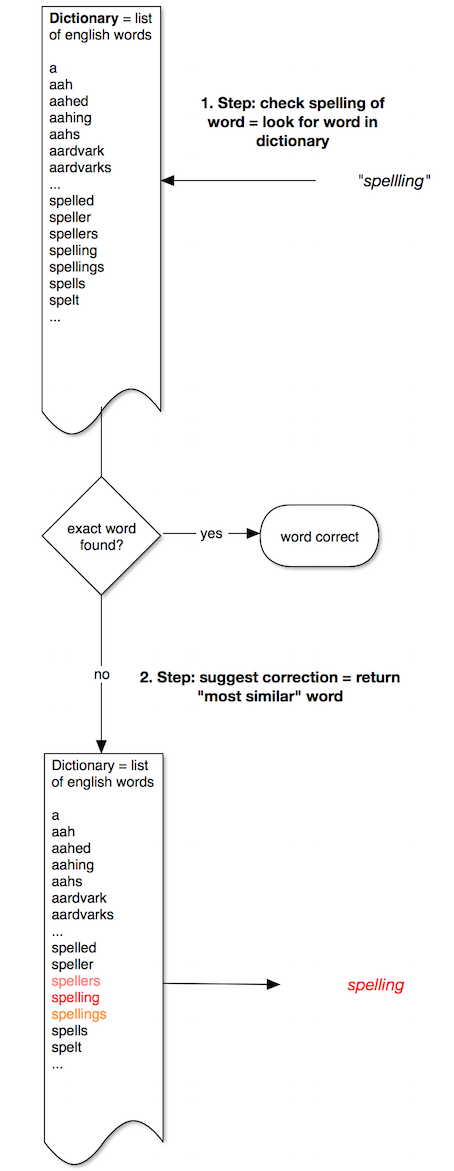
1. Check if a word is correct
The solution is simple: have a list of correct words and check whether the typed-in word can be found in that list. If yes: the word is correct, if not: it’s incorrect. We use the list we have downloaded in the preparation step above.
2. Offer a correction
If a typed-in word is not found in our list of correct words, we want to suggest a correction. The world of correct words of our spell-checker is this list. Therefore, the possible correction must come from it. What we want to do then is to find the word in the list that is “most similar” to the one the users has entered. What “similar” means is still to be discussed, but for now, let’s assume we can find that.
Taken together, our spell-checker can be depicted in this diagram:
Implementation in Clojure
1. Checking if a word is correct
First, we need to decide on the correct data structure to use. Clojure has following collections:
- List: an unordered list of items
- Vector: an ordered list of items
- Map: a collection of key/value pairs
- Set: an unordered list of unique items (no duplicates)
Question: where are going to use a set as our dictionary. Why?
testsolution
We just need a list of unique words and we don’t care about order.
Clojure set
A set is represented in Clojure with
#{elements}or
(set elements-in-a-collection)The first thing to note is that in Clojure there are often two ways to express something. There is the “pure” form, that is called prefix notation4 and looks like this:
(function-name variable-number-of-arguments)So we can define a set as:
(set ["a" "b" "c" "d"])where set is the function name and ["a" "b" "c" "d"] is one argument (which itself is a vector or array of strings).
The set function now does following: giving a collection (the vector), return a set of unique elements. In REPL:
(set ["a", "b", "c", "c"])
-> #{"a" "b" "c"}As sets are used quite often, there is a second way to express it. It’s called a reader macro and considered “syntactic sugar” as it helps the programmer to type less but is not strictly required. The REPL already uses it:
#{"a" "b" "c"} ; same as (set ["a" "b" "c"])There are many other reader macros available in Clojure. For now, don’t worry about this. I’ll introduce more along this tutorial.
Exercise: Another interesting thing happens when typing (set ["a", "b", "c", "c"]) into REPL. What is it?
testsolution
In the REPL answer: -> #{"a" "b" "c"} the duplicated "c" has disappeared. As mentioned above, the items in a set are unique and duplicates are ignored.
Implement the dictionary
Let’s start implementing. First, we need to read the word file into our program. Clojure has the slurp function for this
=> (doc slurp)
clojure.core/slurp
([f & opts])
Opens a reader on f and reads all its contents, returning a string.
See clojure.java.io/reader for a complete list of supported arguments.We can read our words file into a String in Clojure. We name it “words”. In Clojure, we name things with def.
(def symbol initial-value?)Note: the ? question mark means that it is optional (one or zero times in this case). It is possible to name something without giving it an initial value.
Exercise: Edit src/clojure_spellchecker/core.clj. Load the words files that you have copied to “resources/wordsEn.txt” into our program using slurp. Name the resulting String “words”.
testsolution
(def words
(slurp "resources/wordsEn.txt")) Print out the content in REPL:
clojure-spellchecker.core=> (load-file "src/clojure_spellchecker/core.clj")
clojure-spellchecker.core=> words
"a\r\naah\r\naahed\r\naahing\r\naahs\r\naardvark\r\naardvarks\r\naardwolf\r\nab\r\nabaci\r\naback\r\nabacus\r\nabacuses\r\nabaft\r\nabalone\r\nabalones\r\nabandon\r\nabandoned\r\nabandonedly\r\nabandonee\r\nabandoner\r\nabandoners\r\nabandoning\r\nabandonment\r\nabandonments\r\nabandons\r\ ......
We have now the correct word list combined in a huge String and separated by a newline symbol. Next, we need to transform that into a set of words. First, we split the lines. We look again into what Clojure has to offer and soon we find a function called split-lines5. However, this function is not immediately available (as set is for example). It lives in a different namespace6. In Clojure, libraries, functions, variables and so on are organized in namespaces.
We need to add the namespace of split-lines. It resides in clojure.string. We do this by using the ns macro at the beginning of our program file. Leiningen has already added it to us. Change core.clj to:
(ns clojure-spellchecker.core
(:require [clojure.string :as str]))As you can see, we can also rename the reference to cloure.string to just str. That saves typing.
We can use split-lines as follows:
(str/split-lines file))Let’s try it in the REPL.
$ lein repl
clojure-spellchecker.core=> (load-file "src/clojure_spellchecker/core.clj")
#'clojure-spellchecker.core/-main
Exercise: In the REPL, apply split-lines to words.
testsolution
clojure-spellchecker.core=> (str/split-lines words)
["a" "aah" "aahed" "aahing" "aahs" "aardvark" ....
Good. Now we have the words, but there are returned as a list as the square brackets show. But we can convert those easily into a set.
Exercise: convert the list of words that split-lines returns into a set. Functions can be combined by using the result of a function directly as the input of the next, e.g (function-a (function-b parameter))
testsolution
(def words
(set (str/split-lines (slurp "resources/wordsEn.txt"))))If we look at words in REPL, we can see that it has been converted into a set:
clojure-spellchecker.core=> (load-file "src/clojure_spellchecker/core.clj")
clojure-spellchecker.core=> words
#{"ghoulishly" "refraining" "beachboys" "debuted" "protectiveness" "carnie" "overcharging" "flightier" "premiss" "undistilled" "isometrics" "embroiders" ....
However, there is still one problem. Try to find the word “spelling” in the set. It looks like this (assuming you have downloaded the same word list file above):
... "intelligently" "bootlicker" " spelling" "wobbliest" ...
The word starts with a space which can make searching for it difficult and is ugly. What we need is a “data cleaning” step of our word file.
What we are looking for is a way to apply a cleaning function to each element of our list of words. To clean, we can use another function of the clojure.string namespace: trim
clojure-spellchecker.core=> (doc str/trim)
-------------------------
clojure.string/trim
([s])
Removes whitespace from both ends of the string.
This will solve it. But how can we apply this function to each member of our words set?
This is a fundamental process in functional programming. If you come from an imperative programming language background, you’d choose a for (....) loop. In a functional language, this can be solved much easier, with a map function:
(map f c)map will apply function f to each element of the collection c.
Exercise: Extend words the same way you have extended it before: wrap it into another function call. This time add a “cleaning” step by applying the str/trim function to each element of the words array. Add the cleaning step before calling set
testsolution
(def words
(set (map str/trim (str/split-lines (slurp "resources/wordsEn.txt")))))We can implement now a function that tests if a word is correct. We need to check if our words list contains the typed-in word of a user.
Clojure functions
So far we have only used functions. Now we create one. That is done in Clojure with defn:
(defn functionname [parameters] body)For example, Leiningen has already created a function for you. It is the main function (which gets executed by running lein run) and looks like this:
(defn -main
"I don't do a whole lot ... yet."
[& args]
(println "Hello, World!"))-mainis the function name. The minus sign indicates that this function is not visible outside of its namespace.- [& args] are the parameter names.
&is a special sign that allows the function to accept a variable length of parameters - “I don’t do a whole lot … yet.” is an optional doc string we ignore for now
(println "Hello, World!")is the body of the function.
There is (a lot) more to say about functions. The return value of a function is its last expression. In this case, it’s nothing -> nil in Clojure terms. println is not the return value but a feared “side effect” of the function: it does something that changes the environment when executed (printing words on the console in this case). Let’s rewrite “hello word” in a more simplified manner:
(defn hello-world [name]
(println "Hello," name))Type the whole function definition into REPL:
clojure-spellchecker.core=> (defn hello-world [name]
#_=> (println "Hello " name))
#'clojure-spellchecker.core/hello-world
Exercise: In the REPL, execute hello-world. What part of the REPL answer is the side effect and what the return value?
testsolution
clojure-spellchecker.core=> (hello-world "Hans")
-> Hello, Hans <== side effect
-> nil <== return value
Now that we know how to define functions, let’s implement our spell-check function.
Exercise: Go to http://java.ociweb.com/mark/clojure/article.html#Collections and look at the functions that are available for sets to find one that checks if a set contains an item. Implement then a new function called correct? that takes a word and returns true or false
testsolution
; core.clj
(ns clojure-spellchecker.core
(:require [clojure.string :as str]))
(def words
(set (map str/trim (str/split-lines (slurp "resources/wordsEn.txt")))))
(defn correct? [word] (contains? words word))In REPL we test the first step of our spell-checker
clojure-spellchecker.core=> (load-file "src/clojure_spellchecker/core.clj")
clojure-spellchecker.core=> (correct? "absolutely")
-> true
clojure-spellchecker.core=> (correct? "absolutly")
-> false
Let’s continue with the second part
2. Offer a correction
Let’s make our program first a real app by properly implementing the main method so we can execute it via lein run.
What we want to accomplish is this: if the user typed in word is correct, print “correct” to the console and if not a correction like google: “Did you mean …. ?”.
In Clojure, we have the if special form. It is called “special form” because it behaves differently than the rest of Clojure. It has the following form:
(if condition then-expr else-expr)In REPL
clojure-spellchecker.core=> (if (< 1 0)
#_=> (println "one is smaller than zero")
#_=> (println "one is not smaller than zero"))
one is not smaller than zero
nil
We want to use our spell-checker with leiningen. lein run word-to-check executes the main function handing over the arguments which are then available as args in (defn -main [& args]). args is a list of arguments. As we just give one word to check, we can read this word by using (first args).
We want to give this argument a name. Clojure allows that with another special form:
(let [variable-name-pairs] body)Example:
clojure-spellchecker.core=> (let [variable1 1 variable 2](println "variable1 is" variable1))
variable1 is 1
nil
The assignment we define with let is valid inside the body of let.
Exercise: Edit the main function of core.clj. Assign the typed-in word that the first argument of args to a new variable named word. Then, in the body of the let special form, add an if-clause that checks whether the word is correct. If it is correct, print “correct” to the console. If not, print “Did you mean xy”
testsolution
(ns clojure-spellchecker.core
(:require [clojure.string :as str]))
(def words
(set (map str/trim (str/split-lines (slurp "resources/wordsEn.txt")))))
(defn correct? [word] (contains? words word))
; the new main function
(defn -main [& args]
(let [word (first args)]
(if (correct? word)
(println "correct")
(println "Did you mean xy ?"))))With the main function in place, we can execute our app with leiningen:
$ lein run spelling
correct
$ lein run spellling
Did you mean xy ?
We can now implement the last missing piece: provide a correction.
As explained above, we want to find a word that is “most similar” to the user typed-in word. However, deciding what word is “similar” can be very difficult, if not impossible, to answer. For example, if I write “leav” did I mean “leave” or “leaf”? We could derive that by looking at the whole sentence. We could also say that the word “leave” is much more common than the word “leaf” (unless the text is about trees). The similarity of words is a difficult subject and that is where we could later greatly improve our algorithm.
For this tutorial, we start with a simple solution. A common way to determine the similarity between words is the “edit distance” (also called Levenshtein distance7). It goes like this: count the steps I need to get from word A to word B. The words “spellling” and “spelling” have the distance 1, because I need to delete one “l” to get from A to B.
So for our correction, we want to choose words of our word list that have the smallest edit distance to the typed-in word.
Implement Levenshtein distance
We don’t implement this. We re-use an external library. But looking at the Clojure libraries, we can’t find an implementation. Or we may be Java developers and know already a good implementation, which indeed exists: Apache Commons StringUtils has a LevenshteinDistance` method. In Clojure, we can easily use Java libraries.
Using Java in Clojure
As we are using a library that is not part of the core Clojure, we need to add it in two places: in the dependencies of our project, so that Leiningen will download it, and in the namespace.
Edit project.clj and change the dependencies part (you can find the whole file in Github):
(defproject clojure-spellchecker "0.1.0-SNAPSHOT"
:dependencies [[org.clojure/clojure "1.6.0"]
[org.apache.commons/commons-lang3 "3.3.2"]][org.apache.commons/commons-lang3 "3.3.2"] tells Leiningen what to download next time we run it.
Now add it to the namespace. Java dependencies are included in the ns macro with the :import keyword.
(ns clojure-spellchecker.core
(:require [clojure.string :as str])
(:import (org.apache.commons.lang3 StringUtils)))Implement distance function
Finally, we can implement a function that gives us the distance of two words.
Exercise: Implement a function called distance that takes two words and returns the Levenshtein distance of the two words. Use StringUtils
testsolution
(defn distance [word1 word2]
(StringUtils/getLevenshteinDistance word1 word2))Let’s try it in the REPL
clojure-spellchecker.core=> (load-file "src/clojure_spellchecker/core.clj")
#'clojure-spellchecker.core/-main
clojure-spellchecker.core=> (distance "spelling" "spellling")
1
clojure-spellchecker.core=> (distance "clojure" "closure")
1
clojure-spellchecker.core=> (distance "clojure" "java")
6
Works.
Final step
We need to find a word in the dictionary that has the smallest distance to the word the user has typed in.
How can we do that? We get now to the meat of our application!
A general rule for an aspiring Clojure-developer is to first check what Clojure is already offering. We go to the Clojure docs and search there. I like this Clojure cheatsheet8 that has a search box that automatically filters the results (there is also (doc-search "search-term") to search in a similar way in REPL). We are looking to minimize something so I type in “min”.
First, there is min.
clojure-spellchecker.core=> (doc min)
-------------------------
clojure.core/min
([x] [x y] [x y & more])
Returns the least of the nums.
It returns the minimum number of the supplied arguments. This does not yet do it for us. But then there is min-key
clojure-spellchecker.core=> (doc min-key)
-------------------------
clojure.core/min-key
([k x] [k x y] [k x y & more])
Returns the x for which (k x), a number, is least.
This “smells” of a solution. This takes a function k, which returns a number, and returns the minimum of (k x), k applied to the rest of the arguments. For example, return the shortest string (we use count as function k)
clojure-spellchecker.core=> (min-key count "this" "are" "some" "words")
"are"
We have still two things to figure out:
- How can we use our
distancefunction as functionk? - How can we apply
min-keyto our word list?
Use distance function inside min-key
If we try this:
clojure-spellchecker.core=> (min-key distance "spellling" words)
ArityException Wrong number of args (1) passed to: core/distance clojure.lang.AFn.throwArity (AFn.java:429)
Clojure basically tells us: “distance needs two arguments, you supplied only one”. min-key takes distance and applies it to “spelling” but not words. What we need is to have another distance function, that takes the typed-in word as a default and then min-key can take it and apply it to the words in our list.
There is a solution in Clojure: the partial function.
clojure-spellchecker.core=> (def distance-to-spelling (partial distance "spelling"))
#'clojure-spellchecker.core/distance-to-spelling
clojure-spellchecker.core=> (distance-to-spelling "spellling")
1
(partial distance "spelling") transforms (distance [word1 word2]) into something like “(distance [word1 "spelling"])”.
With the partial function of distance, we can implement a part of our solution.
Exercise: Implement a function called “min-distance” that takes a word and returns min-key of a partial distance function and (for now) just two additional words from the dictionary: “spelling” and “spilling”. In other words, fill in following: (defn min-distance[word](min-key <partial distance> "spelling" "spilling"))
testsolution
(defn min-distance [word]
(min-key (partial distance word) "spelling" "spilling"))Let’s test it using Leiningen:
$ lein run spelling
correct
$ lein run spellling
Did you mean spelling ?
$ lein run clojure
Did you mean spilling ?
It works. But of course, as our dictionary contains only two words, the last correction is not satisfying.
Applying min-key with partial distance to our word list
We need a way to apply min-key and the partial distance successively to words. The Clojure answer to this is a function called apply.
apply works similar to map on every item of a collection, but instead of mapping a function to each member of the collection separately, apply unwraps a collection and applies it to each item.
Compare in REPL:
clojure-spellchecker.core=> (apply + [1 2 3 4 5])
15
clojure-spellchecker.core=> (map (partial + 1) [1 2 3 4 5])
(2 3 4 5 6)
Don’t worry if you don’t fully grasp this now. It’s rather advanced. But we have now the right tool to finish our ‘min-distance’ function.
Exercise: Use apply to make (min-key (partial distance word) ...) work with words
testsolution
(defn min-distance [word]
(apply min-key (partial distance word) words))Try in REPL:
clojure-spellchecker.core=> (load-file "src/clojure_spellchecker/core.clj")
clojure-spellchecker.core=> (min-distance "spellling")
"spelling"
clojure-spellchecker.core=> (min-distance "spelling")
"spelling"
clojure-spellchecker.core=> (min-distance "spillling")
"spilling"
It works.
In the very last step, we use min-distance in our main function.
Exercise: Extend -main to use min-distance to suggest a correction. The solution shows the final app.
testsolution
(ns clojure-spellchecker.core
(:require [clojure.string :as str])
(:import (org.apache.commons.lang3 StringUtils)))
(def words
(set (map str/trim (str/split-lines (slurp "resources/wordsEn.txt")))))
(defn correct? [word] (contains? words word))
(defn distance [word1 word2]
(StringUtils/getLevenshteinDistance word1 word2))
(defn min-distance [word]
(apply min-key (partial distance word) words))
(defn -main [& args]
(let [word (first args)]
(if (correct? word)
(println "correct")
(println "Did you mean" (min-distance word) "?"))))That’s it, we have a working prototype:
$ lein run spelling
correct
$ lein run spellling
Did you mean spelling ?
$ lein run clojure
Did you mean cloture ?
$ lein run absolutly
Did you mean absolutely ?
It required just a few lines. Don’t you think that Clojure leads to rather compact and clean code??
Improvements
Of course, we have only implemented a rudimentary solution that can be improved on. The quality of our spell-checker greatly depends on our internal list of correct words. Improving this list would improve the “knowledge” of our app. We could, for example, try to build this list on our own. We could consume the whole Wikipedia and build a new list. That way, our word list would likely improve it’s quality.
Then there is the already discussed problem of “similarity”. One better approach than applying plain edit distance is to take probability into account. Not all words are equally important. If our spell-checker finds words of the same distance, we could choose a word that has a higher probability of occurrence in the English language. Peter Norvig wrote a great introduction9 about this (he also describes a way to test the effectiveness of the algorithm - another point we’d need to tackle).
There are more things to improve on, as performance (our app is not “production ready” yet) and more sophisticated features like grammar and other advanced natural language processing features.
I hope you found this tutorial useful. The whole Leiningen project can be found in github10.
Thanks for reading
I hope you enjoyed reading this post. If you have comments, questions or found a bug please let me know, either in the comments below or contact me directly.
Resources
-
Tutorial Clojure namespace ↩