Using Spring with the Play Framework (2.2.x)
In order to develop modular Java applications, the use of a dependency injection framework is essential. In this post I show how to combine Spring with Play Framework: setting it up, how to use it for action composition and in unit tests and issues that I have found.
Note: I’m using Play framework version 2.2.x and Spring 3.2.5
Library dependency
Add Spring dependency to your project in build.sbt:
libraryDependencies ++= Seq(
...
"org.springframework" % "spring-context" % "3.2.5.RELEASE",
"org.springframework" % "spring-test" % "3.2.5.RELEASE",
...
)In /conf folder add components.xml Spring configuration.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd">
<context:component-scan base-package="... auto wired beans ... "/>
... beans ...
</beans>Controller
Since Play version 2.1 [^version2.1] controller don’t have to be static anymore, which makes it possible to inject them. In your Global.java class override following methods:
protected ApplicationContext ctx;
@Override
public void onStart(Application app)
{
String springConfigurationName = "components.xml";
ctx = new ClassPathXmlApplicationContext(springConfigurationName);
Logger.debug("Loading spring configuration: {}", springConfigurationName);
}
@Override
public <A> A getControllerInstance(Class<A> clazz)
{
return ctx.getBean(clazz);
}Now you can use your controllers by annotating them (I prefer to call my Play controllers “Controllers” and put them in a different package than the default modules package suggested by the official Play documentation):
package api.controllers
@org.springframework.stereotype.Controller
public class MyController
{
// your controller methods here
}In order to enable Spring to wire your controller, you need to configure the base package in components.xml, for example, if the package is named api.controllers you could set it up by adding:
<beans xmlns=...
<context:component-scan base-package="api"/>
</beans>@Autowired beans
You can now wire your bean into your classes. I prefer to put most business logic into services and wire them as needed.
@org.springframework.stereotype.Controller
public class BoardController extends Controller
{
@Autowired
private ServiceA serviceA;
@Autowired
private ServiceB serviceB;
// controller methods
}
@org.springframework.stereotype.Service
public class ServiceA
{
// service methods
}Action composition
One important feature of Play is action composition 1. As Action are going to get wired in it is important to set the correct bean scope2. If no scope is specified, Spring will use the default one which is “singleton”, which will cause weird behavior. Actions need to be created with each instance, so “prototype” is the correct one:
@Scope("prototype")
@Component
public class MyAction extends Action.Simple
{
// Action methods
}Unit tests
In order to run unit tests with wired beans, we need to annotate our spring configuration and class runner:
@ContextConfiguration(locations = {"classpath:/components.xml"})
public class BaseTest extends WithApplication
{
// common test methods
}
@RunWith(SpringJUnit4ClassRunner.class)
public class SomeTest extends BaseTest
{
@Test
public void aTest()
{
// ....
}
}Issues
Last updated: February 2014
Using Play and Spring together, you may encounter following (strange) error message:
java.lang.VerifyError: Stack map does not match the one at exception handler
This seems to happen when using injected classes in a try-catch context. A solution for me was to set _JAVA_OPTIONS like this:
export _JAVA_OPTIONS="-XX:-UseSplitVerifier"
More about this bug can be found here: https://github.com/playframework/playframework/issues/1966
With this, I hope you will be able to use Spring in your Play project and keep it nicely modularised.
Thanks for reading
I hope you enjoyed reading this post. If you have comments, questions or found a bug please let me know, either in the comments below or contact me directly.
Resources
Rules for clean code: be stingy, one-track minded, self-centered and have the attention span of a fly
Is producing quality software art or craft? There are many books (see below) about writing clean code. And even more rules. The problem with having too many rules is that they tend to contradict each other. And some rules may not always be applicable and may make things worse depending on the situation.
Whenever I need to refactor, more often than not I find multiple ways of improving my code. The question is: which one shall I pick?
Is there a core set of rules that always apply and help in any situation? As in an 80/20 manner, where 20% of all the rules count for 80% of clean code?
I think there is. Following are my five candidates.
Top 5 most important traits of clean coders
5. Be stingy and only give what was asked for
Famous last words of projects: “I know the client only asked for requirement X but I made our framework generic so that with our next customer, if he asks for Y or Z, it can deliver that for free!” Yay…
Well, guess what: that next client never came. Instead, the existing client changed his mind and didn’t want X but X’. The generic solution was not prepared for that. And with the over-engineered solution, it was necessary to not only change X to X’ but also Y to Y’ and Z to Z’. And the task to solve X (and X’) become much more complicated and time-consuming.
A clean coder does not try to anticipate the future. He never over-delivers or surprises. What may be great customer service is bad programming advice. Trying to predict future requirements and “preparing for it” so that anticipated requirements can be “easily integrated” is one of the most frequent sources of unnecessary complexity.
Even if it is a hard thing to do, everything that is not needed has to get cut out.
A stingy developer is a refactor-maniac. As a consequence of not anticipating the future, it is necessary to refactor constantly. And that is a good thing. Because it means that it is not the developer who decides what the software should do but the users and clients.
4. Have a one-tracked mind and only worry about doing that one thing
Every method/function/class of a program should do only one thing. And only that one. The one-tracked mind developer only thinks about what that one purpose is a function or method should do.
If every unit of a program does one thing only the overall architecture will layout itself. This is not something that one gets right the first time (at least not me).
Doing one thing also means one level of abstraction. When a problem gets solved neatly by divide-and-conquer 1, the level on which the problem gets solved should be the same for the method.
Sticking to this rule has following effects:
- it keeps functions and classes short. As each part does only one thing it can not be anything else than short.
- it minimizes side effects. This one thing includes of course hidden effects.
- it minimizes surprises. Again one thing and nothing else. No surprises.
3. Be self-centered and egotistical and refuse to be interested in other things outside yourself.
“I don’t want to know”.
Your colleague wants to explain to you all the nice intrinsics of his wonderful class so you can use and enjoy its full potential? Stop him before he starts blabbering and tells him “I don’t want to know”.
A clean coder is not sympathetic. The less she has to know about your code the happier she is. She is only interested in her own code and if your piece of software requires a lot of additional knowledge she gets grumpy.
And of course, this applies the other way round also. The clean coder loathes having to explain how his code works so he will make things as easy as possible for his fellow programmer. The perfect solution is one that is completely obvious and doesn’t require additional explanations.
The effects of this rule are:
- reduced dependencies, as each dependency means something I have to explain the user of my class.
- similarly, higher modularity/independence, as the least I need to know the easier I can incorporate a class, module, method.
- fewer side effects, the evilest type of required knowledge.
- encapsulation/information hiding, which is basically just a nicer way of expressing this rule.
2. Be the shortest lipped person on earth and never repeat yourself
Oh, you know those people. They can never shut up. They tell you over and over again the old stories. Sometimes they come up with an apparently new story but at the end it is same, you have heard all it before.
It’s the all-time classic DRY: Don’t repeat yourself.
Just following this rule, if taken to it’s fullest, can get one very far. There are the obvious cases of plain code duplication, but it can go much further than this. If for example, if we notice in our framework that a similar thing has to be many times, something is wrong.
It is the extension of doing only one thing. My functions may do only one thing but they all may do similar things and should be refactored.
And similarly, DRY + one thing only will lead to a clean architecture. It has to.
By the way: this does not mean to write less code. Quite the opposite, doing only one thing + not repeating functionality often requires writing more code.
1. Have the attention span of a fly and keep all you do stupidly simple
That’s the winner. If my code is so simple that with one glance I can grasp it everyone wins. Even if it is buggy or un-efficient anyone can fix it as it is so simple to understand what it does.
Dead simple code is the result of all the previous rules. It means that a problem has been understood so deeply that we managed to break it down into it’s most basic parts.
Simplicity is elegant. Yes, I may hack my 50 lines of code into one complex beast of a regular expression but then I’m also the only person in the room who understands it. And don’t ask me in one month later for changes. Because by then I will have forgotten most of how I came up with my hack.
Ok, so you might say: “I just keep things simple and I’m done, great advice”. Of course, it’s not that easy, in fact, it is most difficult. That is because software development still is partly art and partly craft. But applying the clean code rules and refactoring/fighting for simplicity every day will get us there.
Simplicity is the most important factor that determines the productivity of the development team. It’s opposite, the mess, that lets cost explode and puts projects to rest.
Resources
Some books I found useful:
- Clean Code and Clean Coder by Martin (probably the most complete list of rules)
- Effective Java by Bloch (if you happen to be a Java developer, this is still my bible).
- Refactoring by Fowler
- Code simplicity by Kanat-Alexander (more aimed at management)
- Code complete by McConnel and The pragmatic programmer by Hunt (talking about more than clean code)
I also recommend pretty much all talks of Rich Hickey, even though they are tackling a rather high-level view of software quality.
Very short introduction to Coursera's Machine Learning course
When I first heard the word “machine learning” I was imagining a robot that I feed some data and that just learns without me doing anything. Doesn’t that sound promising? Why program if a machine can learn for itself? That should be enough to get interested in the subject.
A good way to start learning about machine learning (ML from now on) is by doing the Coursera online class1. I finished that and what follows are what I have learned in simple terms.
Definition
Definition of ML given by Tom Mitchell (1998):
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
So here we have it. Experience E is past data. Some task T is what we want to accomplish. And of course we need measurement P to know how we are doing and to tell if we actually progress.
Supervised and unsupervised learning
There a two types of ML applications that depend on what kind of data the learning algorithm is supposed to work on. One type consists of data of which we know what the “right answer” is. This is called “supervised learning”. A typical example are housing prices. Take house sizes, number of bedrooms, age and so on and predict how much a house will sell for. We know the exact result of such a prediction because it is all in the data.
The data of unsupervised learning on the other hand has no clear answer. The solutions we get from this kind of scenario are grouping of data or clustering. It is trying to find a hidden structure in data.
Learning algorithm
So now that we have data (any of the two kinds) we want to feed our algorithm with it. But what algorithm do we choose? Here comes the statistics part of ML into play. What we are going to use are methods of regression analysis 2, namely linear regression and logistic regression.
Linear regression
To understand the basic idea of linear regression3, let’s assume we have 2-dimensional data like the prices of houses compared to the estate area in square meters. If you plot the data on a 2D coordinate system, a pattern emerges:
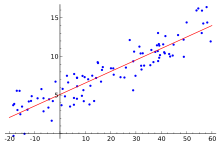
A good algorithm would be one that “comes close” to the pattern of the data: the red line.
This curve is called our hypothesis as it represents our estimate of how to express the data.
But how do we know if our hypothesis is good? In the words of Mitchell, what is our performance measure P?
That is actually quite easy to tell. Just measure the difference between our estimation/hypothesis and the real data. How do you do that? In linear algebra, the difference between two points is the euclidean distance, which is basically the shortest line between two points. The sum of all the distances is called cost function and that is our performance measure.
What is left to do is to minimize the cost function and then we have the optimum learning algorithm.
A lot of the course deals with optimization and the different forms of hypothesis functions we can choose.
Logistic regression
So far we have talked about continuous type of data, like price. To deal with binary data or classification we need a different kind of hypothesis, one that is not continuous but gives us discrete output.
This is the field of logistic regression. Our hypothesis function we use is the so called sigmoid function4:
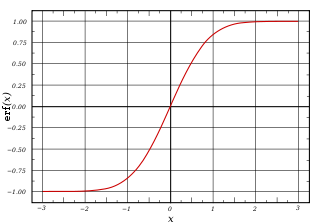
This function goes from -1 to +1. If we define a threshold T, we can assign an output value for f(x) <= T and f(x) > T which gives us the binary output. Again we formulate a cost function and do different kinds of optimization.
Optimization
The basic ingredients of ML are all well known statistical tools. One emphasis of the course is to give a blueprint of how to use the tools. This is the optimization part which makes up the most of the course.
The basic question is this: imagine we have a linear regression problem and come up with following three hypothesis:
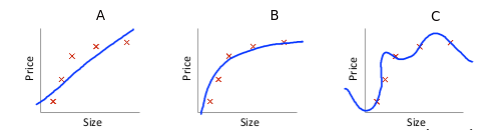
Here we can see three basic problems we face:
- A) underfitting/bias: our learning curve hardly follows the real data. We are under fitting it or have high bias.
- B) good: this curve seems to be a good fit
- C) overfitting/high variance: our hypothesis is too exact, we are overfitting or having high variance.
There are several strategies to overcome bias or variance. Adding regulization, more parameters, more data and so on.
Other subjects
The course has 18 lectures in total. It gives a broad overview about ML. Other subjects are:
- Neural networks
- Clustering using k-means
- Dimensionality reduction
- Support vector machines
- Anomaly detection
- Creating a recommender system
- Learning with large data sets
- An example application of OCR
The exercises
As typical for Coursera classes, there are two kinds of exercises: review questions and programming exercises. The review questions can be repeated as often as you like and change a little every time. I found this to work quite well, especially if trying to get the maximum points.
Then there are the programming exercises. They form the main part of the course. The tasks have to be programmed in either Matlab or Octave.
Personally, I was not very happy with the exercises. I felt there has been a gap between the lectures and the problems that have to be solved in Octave. Some exercises are quite simple, others rather difficult if you don’t know how to approach mathematical problems using a programming language.
Thinking in matrices
The difference between solving problems using a language like Java, Python, Ruby etc and Octave is, what I call, “to think in Matrices”. Many tasks can be solved using an imperative way but the real power of Octave is vectorization of the solution, that is, to solve a problem by applying methods of linear algebra (eg. matrix multiplication). This can be a challenge at first but it does help a lot coming up with elegant solutions.
Conclusion
ML is a huge field. It is easy to get drowned in math but the Coursera course circumvents that by always following practical examples and having the programming exercises to solve. Personally, I’d prefer a more focused approach instead of trying to be very broad but the good thing about this course is that with the first lessons you have already enough to get started in the field. Maybe see you soon doing a Kaggle competition?
See also: Why you should try a MOOC
Automatically matching a category in Google's taxonomy (updated 2017)
Summary
I present an implementation of the taxonomy matching algorithm that was used by my Shopify application (now defunct) to find the most suitable Google shopping category of a product. The product can be defined in free text or tags, the taxonomy is based on Google’s Shopping Taxonomy. I show how to present the problem as a specialised form of text search and how to implement a solution using a search engine. The implementation is available on Github.
Background
In order to list products on Google shopping, merchants have to provide data feeds of their products. Those feeds contain the details about each product that buyers search for on Google’s shopping portal. Product search is different from standard web search in many ways. Advertisers have to pay for listings and search results depend on how accurate the data is that the product feed provides. In web search a google bot is visiting a web page and indexing its content where in product search the merchant is sending the feed content to google. The Google Product Category determines where in the search a product will appear and choosing the most suitable one is crucial.
The Taxonomy
The taxonomy is available as plain text or excel. It is structured as a hierarchical tree with the root being the most basic definition and the leaves as the most detailed.
Some examples:
Furniture
Furniture > Beds & Accessories
Furniture > Beds & Accessories > Beds
Furniture > Beds & Accessories > Bed Frames
Media > Books > Non-Fiction > Body, Mind & Spirit Books
As you can see, the categories are made out of names, ‘&’ and ‘,’ character and ‘>’ as a separator. The ‘&’ is used in different ways which makes the parsing of the taxonomy more difficult. Consider these five examples:
Calendars, Organisers & Planners
Pen & Pencil Cases
Correction Fluids, Pens & Tapes
Home & Interior Design Software
Body, Mind & Spirit Books
Basically, the ‘&’ sign is used in a combinatorial way, a replacement for a comma or part of the category label.
Comma replacement
Calendars, Organisers & Planners are three different elements: Calendars, Organisers and Planners. Another example is Correction Fluids, Pens & Tapes
Category label
Home & Interior Design Software is meant to be just one category, the ‘&’ is used here as part of the label.
Combinatorial
Pen & Pencil Cases is different from all above: the ‘&’ combines words with each other. What it means is: Pen Cases and Pencil Cases.
Unfortunately for us, that means we can’t just replace the ‘&’ sign if we want to get the exact category label. Google went for user readability and not parser friendliness.
The Product Information
The details of a product can be any kind of text. Tags, description or labels.
Example a product description:
The Tosh Furniture Dark Brown Collection brings you this warm and inviting sofa set. Modern and functional, you'll enjoy ample seating options ...
This product could also have tagged with Sofa set for example.
The algorithm
In pseudo code the algorithm for finding matches is straight-forward:
With C = Categories and P = Product descriptions (free text, tags, etc)
foreach c in C:
foreach p in P:
if c match p:
add hit(c) weighted by level of c
select c with most hit points
The only function left to define is match.
Match as special form of search
To make our life easy we will use a trick to implement the match function. We want to find out if a certain category (for example Baby & Toddler Furniture) matches a product description (e.g. Our furniture for babies and toddler). Luckily, there has already be done a lot of work in a field we can take advantage of: information retrieval and search engines. We are going reduce our matching problem to a search task: the category is the search query we want to find in the product description.
That leaves us with the task to redefine a category into a search query and use one of the available search libraries to carry out the search.
As mentioned above, the taxonomy makes varied use of space, comma and ampersand sign.
We keep things easy for our first version (and real life tests show that it seems indeed sufficient): every & and , will be replaced with an OR operator. For example, the category Arm Chairs, Recliners & Sleeper Chairs will be converted into Arm Chairs OR Recliners OR Sleeper Chairs.
As a search engine library, we are using Whoosh because it is a pure Python library that is very easy to integrate. There are of course other more established and better-performing engines (SOLR etc) but as we don’t care too much about performance and have very few documents convenience wins here.
Selecting the final category with most hit points
Now that we are able to find matching categories, we need to select the most relevant one among the matches. The quality of a match, ie the “score” and the “level” of the category, ie. the further down on a branch the categories the more relevant. In other words: an exact match of a category should be preferred and Kitchen Table is preferred to Furniture.
Additionally, we add a weight to where a match was found. If we have an exact match in a title of a product, we want to weigh that higher then if the match was found in the free-form description of a product.
We combine all this into a scoring function which is then subject to fine tuning and experimenting. There may not be a general function that fits all use cases.
Implementation in Python using Whoosh
def index_product_info(product_dict):
schema = Schema(path=ID(stored=True, analyzer=StemmingAnalyzer()), content=TEXT(stored=True, analyzer=StemmingAnalyzer()))
st = RamStorage()
st.create()
ix = st.create_index(schema)
writer = ix.writer()
for key in product_dict.keys():
writer.add_document(path=unicode(key, "utf-8"), content=unicode(product_dict[key], "utf-8"))
writer.commit(mergetype=writing.CLEAR)
return ixThe product information is provided as a dictionary, eg. {'title': 'Halogen Desk Lamp'}. We don’t need to store the index and use an in-memory index (RamStorage). Whoosh offers also the possibility to add a StemmingAnalyzer to our index, that way it is possible to match words in their base form (matching singular, plural and other forms (see Whoosh - Stemming)).
def match(ix, category, weights=None):
# get the leaf of a category, e.g. only "Chairs" from Furniture > Chairs
index, c = get_category(category)
# adjust query
# replace comma and ampersand with OR
query = re.sub('[,&]', ' OR ', c)
with ix.searcher() as searcher:
parsed_query = QueryParser("content", schema=ix.schema, termclass=Variations).parse(query)
results = searcher.search(parsed_query, terms=True)
score = 0
for r in results:
weight = 1
if weights:
weight = weights[r['path']]
score += r.score * weight
return scoreThe actual matching of a category is done by executing Whoosh search on our in-memory indexed product descriptions. Additionally we add an optional weight to each score of a hit.
Github project
I made my implementation available under Github: https://github.com/BernhardWenzel/google-taxonomy-matcher.git. It provides the source code and a script that can be executed by parsing a csv file and writing back the result into a csv file. If you are a shop owner, you can use that tool to automatically assign your products to a category.
Future improvements
The quality of the results can be further improved or adjusted by fine tuning the scoring algorithm of the search engine as well as the scoring function of the selection of the best category match. However, as feedback of our customers show, the settings as they provide already good enough results. At the end, a human still has to double check the results as it is critical to use the most appropriate category for a retailer’s success.
Resources
Creating static websites and PDF files with Jinja and YAML
Why (long)?
It was time again to update my cv. So far in my working life, I have created my CVS using Word (ugh), Latex (indeed) and recently Django! Django? Yes, creating a web page and then having it rendered to PDF with the Pisa library. This grew out of an idea to create my homepage and my cv PDF from the same base.
That was working quite well. Using Django’s ORM and fixture mechanism I was able to maintain web content and my curriculum using the same base of YAML files. However, my website as well as my cv are rather static in nature and using Django felt like a huge overkill. Besides, I wanted to move my site to S3 and in my constant quest to simplify things I decided to throw out Django and just use plain Jinja templates and YAML files as my content.
Why (short)?
To create static files I prefer to have my content in flat text files in a convenient human-readable form. Therefore my choice of YAML. To bring the content into a nice looking layout, I wanted to re-use what I already had so I chose Jinja templates (which is, in fact, my favorite template engine).
1. Content = YAML
YAML documents are instantly understandable and can map most common data structures (see wikipedia article for an introduction).
YAML files can be processed in python using PyYAML. The usage is straight forward:
from yaml import load, Loader
# load entries yaml
data = load(open("data/entries.yaml"), Loader=Loader)
Depending on the YAML definition, the data object will be a map or list with the content.
2. Template = Jinja
With the data object at hand, we can render our templates into an HTML object cv.
from jinja2 import Environment
env = Environment(loader=FileSystemLoader("templates"))
# create and render template
template = env.get_template("cv.html")
cv = template.render(entries=data, templates_folder="templates")
Now comes the interesting part: how do we select the data in our templates? We can make things very easy if we define the data in the YAML files in a beneficiary way.
All can be done using this Jinja’s test functionality: {% for element in data if condition %}
Let’s say our YAML definition looks like this:
- details:
name: Bernhard Wenzel
address: Street, City, Country
- projects:
title: Development of sports site
client: BigCorp
And we load the whole data content into entities. To select only the address field we can use the following test:
{% for e in entries if e.details %}
{{ e.details.address }}
{% endfor %}
if e.details selects the correct list element (in YAML, elements that start with a minus sign are list elements). Voilà. The condition can be any expression of course. For example, in order to disable certain entries, we could add a field enabled: false to the YAML file and filter it using if ... and e.enabled.
Sorting is also possible, in my case it is already sufficient that the order of elements in the YAML file is preserved in python, so keeping things in the correct order in the file is all I need.
We can get quite far this way without any further querying.
3. Write PDF
The rendering to PDF is now just a matter of using the pisa framework. I prefer to have the filename containing a date:
import ho.pisa as pisa
cv = template.render ...
# create pdf
date_format = "bernhardwenzel-cv-%Y.%m"
filename = "out/" + date.today().strftime(date_format) + ".pdf"
pisa.pisaDocument(StringIO.StringIO(cv.encode("UTF-8")), file(filename, "wb"))
I have setup a small GitHub project including an example template that I’m using to render my cv. Available at: https://github.com/BernhardWenzel/pycvmaker
Creating static websites
As the PDF is created by using the rendered HTML file, it is, of course, possible to create a static website that way. There are plenty of static website generators, among those I use Pelican and Octopress. But to keep things even simpler and as my website is not a blog and rarely updated, I prefer to create static content straight out of Jinja.
I use Staticjinja for this which basically combines template rendering and creating static output in one step.
It is possible to call staticjinja directly, however, in order to pass in data a small script is necessary. For my website at wenzel-consulting.net, I use this little snippet:
def get_data():
return {
"entries": load(open("data/entries.yaml"), Loader=Loader),
"projects": load(open("data/projects.yaml"), Loader=Loader)
}
if __name__ == "__main__":
output_folder = "out"
# remove out
shutil.rmtree(output_folder, ignore_errors=True)
renderer = Renderer(outpath=output_folder, contexts=[("index.html", get_data)])
renderer.run(debug=True, use_reloader=False)
# copy static folder (css and images)
shutil.copytree("static", output_folder + "/static")
That’s all. I use the same way to filter my data as described in step 2) and it does all I need.
Optional: deployment to Amazon S3
While I’m at it here’s how I deploy the static website to S3. Setting up an Amazon S3 container to serve as a host for static websites is a matter of a few steps (and it’s reasonably priced). Instructions can be found on Amazon (basically, create a container, enable static hosting, make container public and setup routing if you want to use your own domain).
As a deployment tool I use is s3cmd (install with sudo apt-get install s3cmd and configure s3cmd --configure).
To update my contents the sync command can be used. Let’s say the static files are under <project>/out and I have an S3 bucket named <BUCKET-NAME>. To deploy, I do following:
cd <project>
s3cmd sync -r out/ s3://<BUCKET-NAME>
Note: the trailing slash of out/ is crucial. Without it, the command copies the folder including the out directory, but to copy only the contents into the root folder of my S3 bucket the slash has to be added.
That’s it. Now I can structure my content in any way I wish using YAML and render it in a flexible way with Jinja templates.
Resources
- My github project for creating a curriculum out of YAML files: https://github.com/BernhardWenzel/pycvmaker. Comes with sample html & css & yaml files to get started.
- More about Yaml: wikipedia article.
- Jinja template engine.
- s3cmd tool