And then Covid happened - Resilience as a blogger
Mike Tyson knows a thing or two about the meaning of disruption when he says that “everyone has a plan until they get punched in the mouth”.
Something similar happened to this blog. I had planned to write consistently on a regular publishing schedule (writing after hours and weekends) and even accounting for a major (but happy) change of welcoming a new family member. I was ready. But the pandemic had turned everything upside-down. I was confronted with a sudden, unexpected disruption that my blogger persona was not prepared to deal with.
Strategic planning involves predicting the future. Unforeseen events are, by definition, excluded from any consideration. If those do happen, something else matters - the inherent ability to bounce back from a sudden change. This is called resilience.
In systems engineering, resilience is defined as
… an ability of the system to withstand a major disruption within acceptable degradation parameters and to recover within an acceptable time 1
Applying this definition to this blog, the service degradation (little to zero article output) and time to recover (months) were both not acceptable.
But like most people, I hold more than one role in life - I’m also an employee, parent, partner and so on. Since this blog doesn’t pay my bills, other services I provide were more important to maintain.
Fast versus slow disruption
Most of the time, when we think about resilience, we are talking about dealing with a sudden disruption - a pandemic, hacker attack, a new competitor, key employees leaving a company and so on.
However, harder to handle is gradual change. Service degradation is a temporary measure to gain time for dealing with a problem. This won’t work if the underlying cause can not be fixed immediately and requires a long-term adjustment.
Skills that slowly become obsolete is a prevalent example. Companies can deal with a skill shortage by hiring workers with the right expertise. But there is a limitation to how quickly it is possible to find and integrate new employees.
Even more restricted are individuals. The worker that has been laid off and finds that their skills are not in demand anymore will need time to acquire new expertise.
A better strategy to deal with slow change is constant gradual adaptation. Companies can train their workers and implement a culture that encourages learning. Workers that keep updating their skills doing their day-to-day job stay employable.
That is not always easy to accomplish. The interest of companies is stability. If in-house technology is mastered and fulfils business needs, there is little incentive for stakeholders to change anything. No new investments will be made just for the sake of helping employees to update their skills.
Some companies understand this and allow employees to spend a certain amount of their time to pursue personal interests. This is a start but doesn’t help if no guidance is provided on how to spend the time wisely. Our education system does not prepare students for a world where constant learning is required. This problem is amplified when it is not clear what technologies will stay relevant.
It is therefore beneficial to invest time into acquiring skills that have a long half-life. The author of this post believes that blogging is such a skill. Writing regularly, and in front of an audience, is an exercise in thinking and clear communication. Those are true meta skills that are useful for most of current and future jobs.
The Pioneer in Software Development
Concepts from the military can often be useful to explain ideas in different areas like business or technology (as it is the case for this blog - the word “strategy” is deeply rooted in warfare).
For example, consider the role of a pioneer in the military.
Wikipedia 1 2 defines this type of soldier as follows:
Historically, the primary role of pioneer units was to assist other arms in tasks such as the construction of field fortifications, military camps, bridges and roads
Pioneers are enablers and fixers. They pave ways, fix broken infrastructure and secure beachheads. They often march in front of an advancing army to secure new terrain.
There are phases in a software development project that require a similar type of pioneering work. Often, this work is done by software architects.
Mostly two types of situations come to mind:
- The need for a proof-of-concept work
- Investigation of a notoriously difficult bug
Continuing with the metaphor, when we implement a proof-of-concept project, we are exploring new territory in the hope to secure a (strategically) important landmark. This can mean to make sure a new framework or platform works the way we expect it to do, trying out a new implementation of an algorithm or testing the feasibility of an idea.
Fixing a notoriously difficult bug is the equivalent of helping an army that got stuck by fixing broken infrastructure like bridges or train tracks. In the world of software development, this goes beyond mere bug fixing. I’m talking about a situation where debugging a problem has become so difficult that usual ways don’t work anymore. This can happen, for example, when, for whatever reason, a team had to make so many changes at once that the number of unknowns made narrowing down the problem impossible. In those cases, it can be better (or might be the only feasible option) to re-create the environment with only the minimum dependencies (or even less) and stripping away everything else. Starting new from scratch, or to be more exact, starting from the last known working state and moving towards the desired, non-working state.
Rules of pioneering work
- Pioneer code is meant to be thrown away. The moment we understand how the new framework works and that it does what we expect from it we are fine and can move on. Pioneer coding is coding to gain knowledge, not to deliver functionality.
- Speed matters. Code can be as ugly as needed because we only want to get from start to finish as quickly as possible.
- We need to keep the number of unknowns to a minimum. The goal is to move from one working state to the next.
- The second rule of pioneering club is … yes, really, the code is meant to be thrown away. It might be tempting to use the code as a base for a new project but as stated above, quick & ugly is the motto and we don’t want that as the basis for any serious development.
The downsides of pioneering work
- Expect reluctance from management because pioneering work can look like a waste of time and money.
- Expect reluctance from developers because being deliberately fast and forget rules of clean code can push some people out of their comfort zone
- Due to the uncertain nature of pioneering work, a higher degree of ownership is required. There is no clear specification or feature request which feel unmotivating for some.
The upsides of pioneering work
- It can feel like fun and play. It can be liberating not having to worry about code quality with the only goal to gain understanding
- Starting from scratch with only the bare minimum and everything else stripped away can lead to a significant understanding. Often, we can’t see the forest for the trees and just by starting small things become clear
- Deeper knowledge leads to deeper developer happiness. And helping others to get unstuck can be very rewarding
IoT Architecture Models
A common way to describe an IT architecture is to use abstraction layers. A layer hides away implementation details of a subsystem, allowing separation of concerns 1. In other words, a layer is only aware of its sub-layer (but without knowing the inner working details or further sub-layers) and does not know anything about layers above.
Many attempts have been made to model an IoT architecture using layers. Depending on what specific challenge a model tries to solve, the focus can be on different viewpoints, for example, functional features versus data processing.
In the following diagram I bring two common models together.
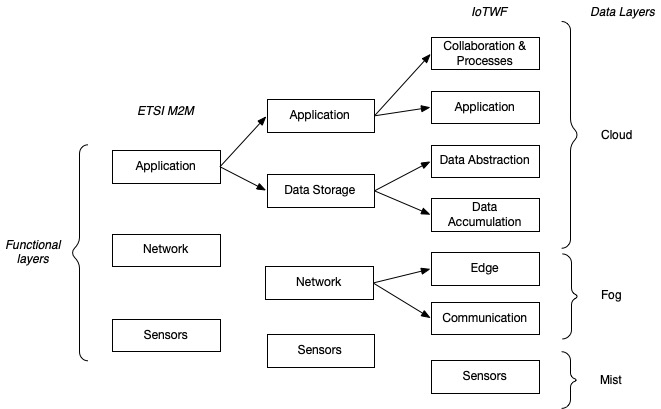
On the left we have the three layer functional model defined by the ETSI Standards group 2.
- The basis is sensors and physical devices
- A sensor has to send data over a network, which is the layer above the sensors
- Finally, data gets processed by some kind of application, the top layer
This model is mainly used in the context of machine-to-machine (M2M) communication.
In the middle model, we split data storage from the application layer.
On the right we reach the 7 layer model defined by the IoT World Forum 3.
- The network is further separated into a communcations and edge processing layer
- Data storage is divided into data accumulation (raw data storage) and data abstraction (data post-processing).
- Finally, the application layer is the basis for another layer of standardised collaboration and processes.
Another viewpoint is to look at where data is processed (credit to the excellent IoT fundamentals course available on O’Reilly4 which goes into more detail about models mentioned here): at cloud, fog or mist level5.
This introduces a different viewpoint focussing on data processing. At the mist level, data processing occurs right where sensors are located. The fog level lies below cloud where the infrastructure connects end devices with the central server. The cloud is the final destination.
Quality attributes of a cloud mock testing framework
Following up on my last article about how to evaluate technology options I’d like to take one example and describe how to evaluate cloud mock testing frameworks.
The context is that in my work we had to choose between two popular AWS testing frameworks, namely Localstack1 and Moto2.
I won’t go into the details of the two choices (I leave this for another update), but explain the first step of any evaluation process: making a list of categories that we use to compare the options. This is mostly a brainstorming exercise, with the goal to have a list of attributes that is exhaustive and mutually exclusive.
List of categories
Ease of use
This might be the most important attribute. Because quite often, testing is seen as something useful and required but annoying to do. And I believe the reason for that can be found in something I call developer laziness, which I mean in a positive way (including myself in that category)!
We developers are inherently lazy and that’s why we have an urge to automate mundane tasks as much as possible. This is a subject for another article, what is relevant here is that the if a testing library makes writing tests harder to do, there will be a negative effect on the overall quality of testing.
Ease of use can be subdivided into further attributes:
- does the framework change the way we write tests?
- does it integrate well with our existing tools (e.g.
pytest?) - does it become easier or harder to write tests?
Ease of debugability
I’m unsure if that is actually a word (however, wikipedia3 does list it as a system quality attribute), but it is easy to understand in our example: does the framework help us with debugging our code?
The main purpose of testing is to make sure the code we write does what it is supposed to do. But very often, writing a test has another advantage: it makes debugging simpler (sometimes local testing is even the only way to debug code).
This is certainly true for software that runs on the cloud. It can be difficult to debug code that depends on remote services. Having a local mock simplifies that a lot.
Completeness and Correctness
These attributes are binary in the sense that if a framework doesn’t meet those requirements we can’t use it.
Completeness. With that I mean: does it the framework mock all the services we want to test? If not, we can’t use it.
Correctness. Does the mock behave the same way as the real service? If not, we obviously can’t use the mock.
Speed of execution
The longer testing takes to execute, the more reluctance we have to use it. Long execution time can become a major efficiency problem.
Other categories
- Licensing cost (in our case not relevant as we compare open source frameworks)
- Available support, popularity, long-term availability
How to evaluate technology options
As mentioned before, the answer to the increasing complexity of technology is to provide ever more frameworks, tools and other solutions. Everyone involved in development has to evaluate and choose among options constantly.
Quite often, we use what we know. I call this “developer laziness” and I mean that in a good way. If a tool is too complex to use or understand, it has to provide a substantial advantage to warrant convincing others to invest the time and effort to learn how to use it.
However, not looking beyond what we currently know severely limits the ability to increase the quality of our software implementation. It is especially the role of an architect to find new and better ways to improve the status quo and explore alternatives.
Comparing technology choices is a three step process:

The steps are as follows:
- Make an exhaustive and complete list of categories that we can use to compare the features of each option. This list should be MECE1, which is an acronym for mutually exclusive, collectively exhaustive. It’s a binary list of categories that encompass as much area as possible.
- With this list in hand, research answers. This includes talking to experts, reading documentation and implementing proof-of-concept mini projects
- Fill in the answers, prioritise, weigh categories and then come up with a conclusion.
Step 1) is a brain-storming exercise. I find it very useful to involve other members in this step. If you do so, I recommend having everyone make a list on their own and then merge the findings into a list. Having more than one person come up with categories increase the chances that our list is exhaustive. The final merge of all answers into a final list can be best accomplished by one person to keep the list mutually exclusive.
Step 2) is then best done by the expert of that field. If the technology we explore is new (which quite often it is), implementing a quick proof-of-concept is an effective way to get a “gut feel” for the technology.
Presenting Step 3) is then best done with the team and in front of the stakeholders. If the choice we have to make is substantial, the desired outcome of the process is to give the stakeholder a clear picture of the pros and cons and enable her to make an informed decision.
One question is how much time we should spend on this process. The more important the decision the more thorough we have to be. It is important to make the evaluation of technology itself a task that has resources and time allocated to it. The only way to find a good solution is to thoroughly understand the problem and that requires to give importance to the evaluation process.
I will come back to this process many times with concrete use cases.