First Git Mental Model

We make sense of the world through models we create in our minds. How well we understand reality depends on the accuracy of those models. However, we are often not aware that our internal representation can be inaccurate or, worse, we may not even realise that we use mental models at all. By bringing our thought processes into the open, we can shed light on the gaps in our understanding and learn more efficiently.
I have written about the role of mental models in software engineering. I recommend reading that first if you haven’t done so, as it explains the main idea. In this post (and more to follow), I take an existing tool, framework or subject and look at it through the lenses of mental models.
Today’s example is Git. It assumes little or no prior knowledge. If you are already well-versed in Git, I encourage you to keep reading nonetheless. The goal of this series is as much teaching a specific subject as it is about exploring how to construct good mental models in general. There is no shortcut to achieving accurate understanding. As good as an existing mental model may be, we still have to absorb and make it our own; we can’t just copy and paste it into our brains (unfortunately).
What is Git?
The official definition says this:
Git is a distributed version control system.
Does reading this sentence evoke any mental images for you? In my case, the word “distributed” brings to mind several computers running in distant locations. “Version control system” lets me see software that stores copies of documents in an orderly fashion.
This is rather vague. A better way to understand something is not to ask “what” it is, but “why” does it exist - what is its purpose?
What is the purpose of Git?
There are primarily two problems Git is trying to solve:
- How can multiple people work in parallel on the same documents without stepping on each other’s toes?
- How can we provide a safe environment for making changes without worrying about losing previous work?
2) is part of the solution for 1). However, it is also possible to only take advantage of 2) while ignoring 1) (if you use Git solely as a local version tracker, which is a legitimate use case).
1 - How can multiple people work on the same documents at the same time?
Let’s think about 1) - there is a group of people who want to work on the same set of documents simultaneously. How can they do that? Pose that question to yourself, and your brain will immediately start generating possible answers.
Depending on how much experience you have with a given problem, the solution you come up with can be complex or straightforward. A natural way to find a solution to a problem is to search in our memory for a similar situation that we can apply to the new challenge. How do people typically collaborate?
I see an office where several people are sitting around a table, with paper documents spread out in front of them. They pass files around, discuss changes, use pencil and eraser (or scissors and tape) to make changes.
Something like this:
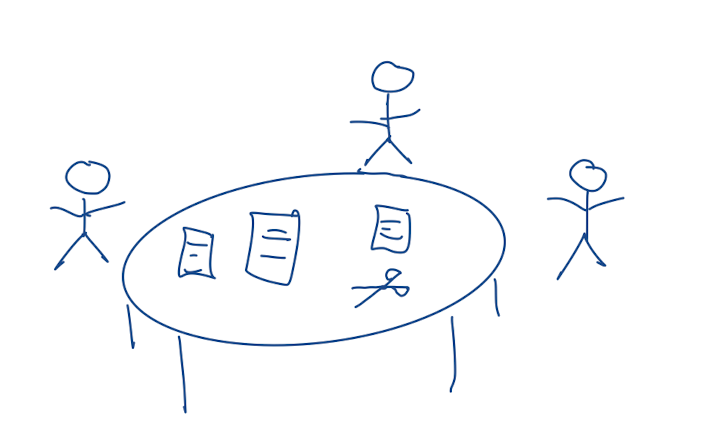
Although this model describes collaboration, the participants can’t work in parallel, as they need to take turns to change a document. Let’s refine our model by having everyone work on copies instead of the original documents. To reflect that Git is a distributed system, we also let each worker have their own table.
Our new model looks like this:
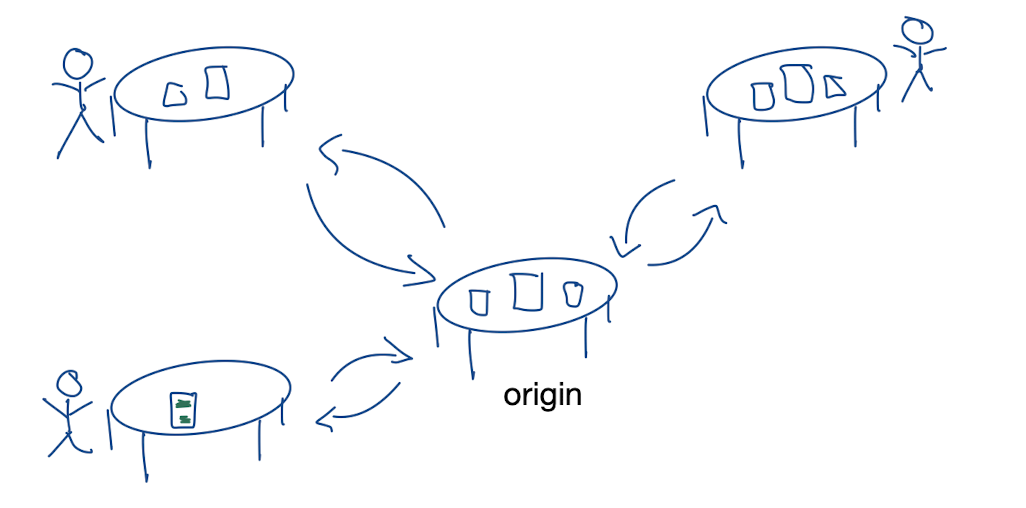
How would that work? The table in the middle (let’s call it the “origin” table) contains the original documents. If I want to work on them, I first make copies of the documents and then grab one of the tables and go about making changes as I please. Then comes the moment to update the originals. I go back to the origin table and replace the sources with my edited copies.
There’s just one problem: what if someone else has already changed the originals? If I swap the documents, their changes will get lost.
So instead of swapping out entire documents, I need to “merge” my changes with whatever is on the origin table. This works most of the time, except when my change and someone else’s change are in “conflict”. For example, in a design document, someone changed the color of a button from red to green, but I changed it from red to yellow. Who’s change should persist?
A conflict:
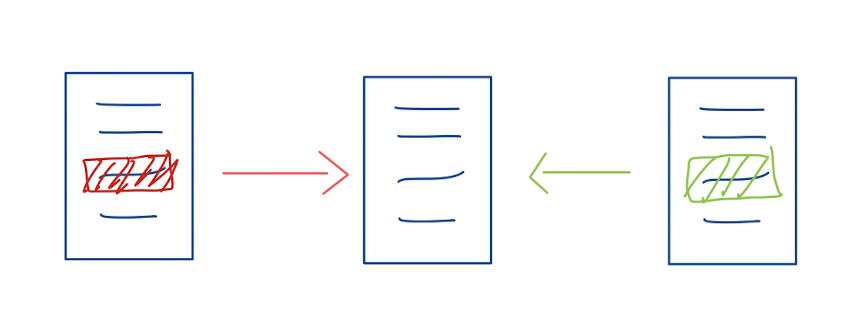
I want to keep my version, but what if I change my mind later (because it turns out my colleague was right)? That is the second problem Git solves: as long as we track changes and can revert back to a previous state, we are safe to make changes.
How does Git make that possible?
Assume I have no spontaneous idea. We are then at a typical state during the learning process. We have exhausted fleshing out our mental model (or don’t want to speculate anymore), and we encountered a few areas where we can’t satisfyingly figure out how things work in reality.
This is a good moment to do some research and consult a book or a manual.
Sidenote: why start with the mental model?
You may ask why we didn’t start reading the book before building our model. Aren’t we wasting our time trying to come up with an explanation of how things work without having done research first? I disagree. By having made our current knowledge visible, the subsequent research becomes more targeted. We can locate gaps more quickly, know what kind of information we need or don’t need, and have a map to place new information.
2 - Keeping a log of changes
So how does Git keep a log of changes?
I use Pro Git as reference documentation. A good chapter to start is What is Git?, you may want to read it now.
The main point from that chapter leads us to the answer to our question:
Git maintains snapshots of changes, not diffs
In other words, every change in Git is stored as a snapshot of all files. Note that the word “snapshot” is another mental construct. Like a camera that catches a scene at a specific moment, a snapshot in computing is a copy of an entire state of a system at a certain time. We can use that information to extend our mental model.
Besides working on our copies of the original documents, we create additional copies of the copies and put them in boxes. Each box reflects a document change. To keep a log of changes, each box links to the previous box.
It looks like this:
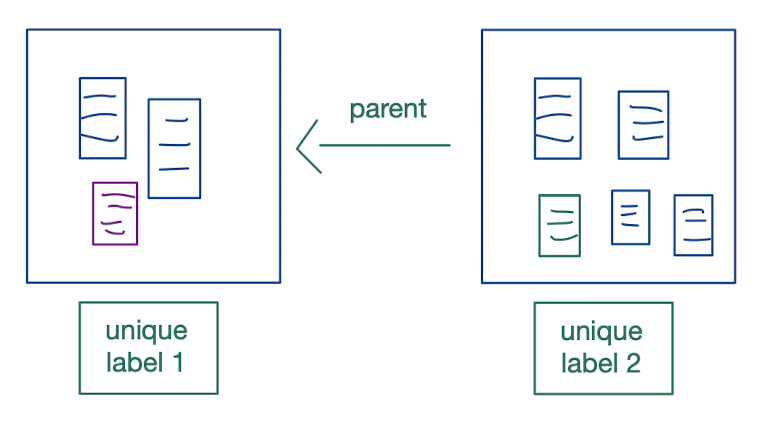
Those boxes are uniquely labelled. As you may have read in the book, Git creates so-called hashes of documents (you’ll find hashes everywhere in Git). A hash is a string of symbols that is unique for any possible state of documents.
Sidenote: focus on information to fill the most important gaps, ignore the rest
You may want to dig deeper to understand how hashing works under the hood. Or not? That is another common stage of any learning process. The question is this: should I figure out the inner workings of hashes, or should I just accept that they work in some way and move on?
Your mental model can guide you here as well. At this point, knowing how hashes work won’t help you with your understanding of Git. It won’t increase the accuracy of your model at this stage (being a beginner). It is the wrong rabbit hole to go down. Instead, for the sake of simplicity, we accept this gap in our understanding.
Good mental models strive for simplicity by conveying just enough details that are required to reliably predict the behaviour of the thing you are investigating. Any additional information will slow down progress (more about this at the end).
Log a change - but when?
Back to Git. Another question remains: when do we take a snapshot? Could we store every change? That would create an insurmountable amount of data and not be feasible.
Instead, what seems practical is that the author decides when to store a snapshot. Only they know when changes have reached a meaningful state that should be preserved.
How does Git make that possible?
The same Pro Git chapter mentioned above answers that question. The relevant paragraph is called “the three states”.
Three states
A file in a Git repository can have three different states: it is either “untracked”, “staged”, or “committed”. Untracked files (or modifications) are not recorded yet. When files are “staged”, that’s the moment when we intend to take a snapshot (but we haven’t registered the change yet). Committing files is the final step of storing the snapshot.
The three states:
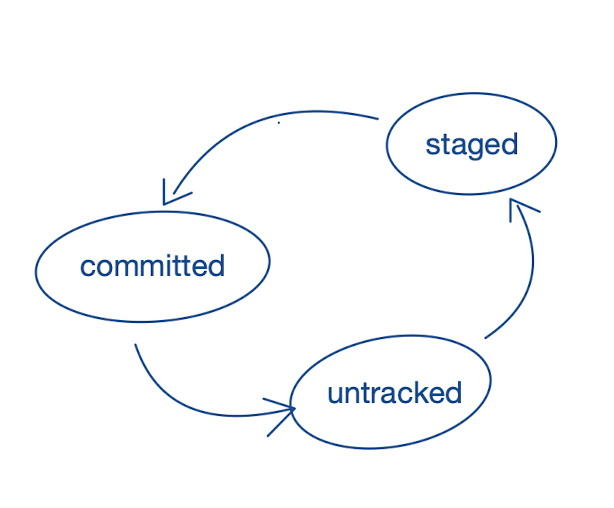
Coming back to the question of when to take a snapshot, the answer is that it is up to the user to make that decision.
By the way, Git introduces three states, although two would have been sufficient (e.g. committed - or not committed). The intermediate staging step makes preparing a snapshot easier, as we can add or remove files and change our minds before creating the record.
Testing our model
We have developed a set of mental models that cover the basics of Git. It is time to test the usefulness of those models by asking ourselves if they can sufficiently explain how things work for our purposes.
Branching
What is a branch? The word is already evoking a mental model of a real tree, with its main trunk and branches diverging into new directions.
You can read in detail about Git branches in Pro Git, but we can already explain how branches work in principle. As discussed above, “how Git creates a log of changes”, a branch is nothing other than a series of snapshots that is different from the main development flow. Internally, Git uses pointers to make that work, but all we need to understand now is that changes are stored as snapshots and that each snapshot has a unique label (hash) attached to it. If you want to know if two branches are the same, all you have to do is compare the hashes.
Git commands
We test our model by looking at basic Git commands that you will likely have encountered when you first learned about Git.
git clone
git add
git commit
git push
git pull
If you are new to Git, I recommend running git COMMAND --help and start reading through the first paragraphs to see if the explanation fits our mental models.
git clone --help says
Clones a repository into a newly-created directory, creates remote-tracking branches for each branch in the cloned repository (visible using git branch –remotes), and creates and checks out an initial branch that is forked from the cloned repository’s currently active branch.
We may not fully understand every detail, but the overall idea fits our distributed tables model of making copies and branches.
git add --help
This command updates the index using the current content found in the working tree, to prepare the content staged for the next commit.
We don’t know yet what an index is but can explain most of what is said here with the three stages model. And we learn that git add moves changes from “untracked” to “staged”.
git commit --help
Create a new commit containing the current contents of the index and the given log message describing the changes.
Same here, and now we can conclude that the “index” tracks changes that have been “staged”.
git push --help
Updates remote refs using local refs, while sending objects necessary to complete the given refs.
We don’t know what a ref is but “sending objects” fits our model where we bring our documents to the “origin” table and merge our changes.
git pull --help
Incorporates changes from a remote repository into the current branch. In its default mode, git pull is shorthand for Git fetch followed by Git merge FETCH_HEAD.
This does not fit our mental model. So far, we said that when we are ready with our work, we bring our changes to the “origin” table. But in reality, we “pull” changes down to us. We found a gap in our model. Coming back to Pro git - What is git? we can now understand what is meant by Nearly Every Operation Is Local. If Git was new to you and you followed along with the steps of this article, I bet you have now a stronger understanding of what “everything is local” means compared to when you first time read about it.
“Real-life” testing
The ultimate test occurs when we apply our knowledge to real-life situations. Whenever Git does not behave as expected, we find out where we need to improve the model.
Polish & refine
As mentioned in the introduction post, building mental models is a four-step process:
- Define your model. We all use some kind of model, whether we are aware of it or not.
- Test your model. Either by researching or in real-life situations.
- Improve your model. Take what you have learned in 2) and improve it. Then test again.
- Simplify or go deeper. There will come a moment when steps 2) and 3) won’t bring any further improvements or when the model does not go deep enough because you have advanced in your understanding and tackling bigger challenges. You may be at a point where you can significantly simplify the model or build a new one.
We have not yet exhausted steps 2) and 3), but we can still simplify our model. The table metaphor has gaps and is not that useful (but it helped to develop the model of snapshots).
Instead, the model of snapshots and the three file states together seem to be a good first mental model of Git.
The final Git mental model
Log of hashes & three states
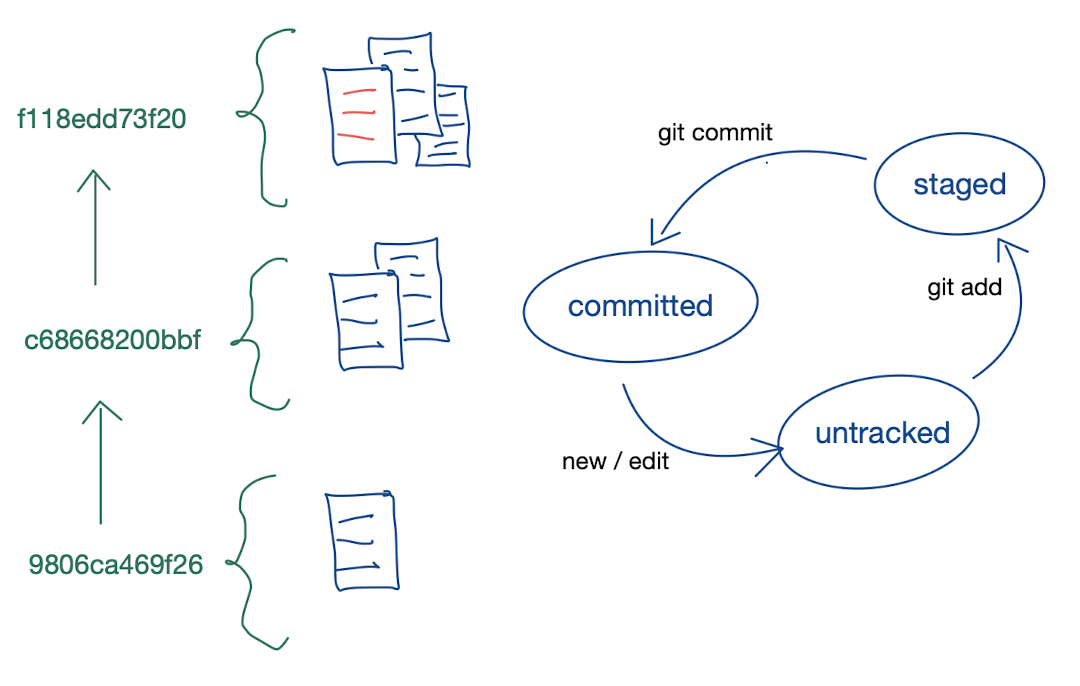
- Every committed change in Git is stored as a snapshot and referenced by a unique hash. A log of changes is represented by a log of hashes. To compare two branches, all we need to do is compare the hashes to know if they are the same or not.
- All files go through three possible states.
Summary
While developing an understanding of how Git works, we have gone through the process of constructing mental models. The key takeaways are the following:
Always build your mental model first. Before you start reading a book or tutorial, sit down and visualise how you believe that the thing you are interested in works. That will make your subsequent research a lot more efficient, as you have a base that guides your reading and a place where you can place new information and relate it to existing knowledge. Remember the last time you read a book without any preparation. You may have highlighted sentences and written some notes in the margins - but how much of that information could you actually remember?
Test and refine your model. That step is easy to forget, especially when it comes to improving your mental model. When you hit a plateau in your learning effort, that is the moment where you need to go back to your model and work out where the gaps are.
Just enough information Good mental models are simple, some even elegant, and they convey just enough information to be useful.
The goal is not 100% correctness. A model is always an approximation and depends on your context and level of understanding. Don’t try to cram everything in it. Instead, figure out what are the most important facts of something. That exercise itself is very valuable to master a skill.
Next
With the model at hand, we can now go and apply it to our daily work.
A good idea might be to look at your .git folder and try to figure out what is going on there. That will give you a deeper understanding of the internals (the relevant chapter in Pro Git is Git Internals Plumbing and Porcelain).
Or even better, don’t do anything and just use Git and wait until you hit a bump. That is the beauty of learning with mental models. There is no fixed path that you have to follow - real-life situations will show you where you need to improve.
I will come back to Git in a follow-up post and apply the model to more advanced situations, showcasing examples of where our model is sufficient and where it is not.
Software Mental Models

Software engineering is a rapidly evolving industry, putting developers in a perpetual state of having to learn new things while doing their actual job. This is a daunting task, not only because a full-time job leaves little room for training and catching up on the latest changes in tech, but also for the reason that it is becoming increasingly more difficult to decide what and how to learn.
For example, when faced with an engineering problem, the following questions may pop up in a developer’s mind:
- Should I search the internet for a quick answer, hoping to find a copy-and-pasteable solution to my problem? This may or may not work. Often it leads to fruitless attempts and wasted hours.
- Or should I better take out that textbook and try to understand the fundamental ideas? But books are long - where do I start? Maybe a shorter video is a better use of my time?
- Or is it time to get more practical experience instead of indulging in theory and pick up a tutorial or work on a proof-of-concept?
- Why do I seem to have hit a plateau of my understanding and what is required for me to move ahead?
- Why do others appear to grasps things faster while I struggle to get my head around this problem?
As we can all testify, the issue is not that there isn’t enough information to solve a problem. It is the opposite: how can I make sure I invest time in the right activity to learn as efficiently as possible?
I believe there is an answer to all those questions and that it is possible to be confident about what and how to learn. The answer can be found by paying close attention to how we learn.
What does it mean to understand something? Understanding is related to knowledge. The deeper my understanding goes, the more “complete” my knowledge. Gaps in knowledge, on the other hand, are causing a lack of understanding. So when is my understanding “complete”?
I offer the following definition:
My understanding is complete if my knowledge about something is sufficient enough so that I can reliably predict future behaviour.
The ability to reliably predict the behaviour of the thing or process I’m interested in determines my level of understanding. The fewer surprises I encounter, the more I can explain behaviour, the deeper my understanding.
However, all this depends on the purpose of what I’m doing and how deep I need to look into something.
For example, I don’t need to understand how bits are moved on a chip to program a website that runs on a standard server. Knowing about hardware would not increase my ability to predict the behaviour of my code. However, move away from a traditional operating system to specialized hardware, and the situation changes. Now my knowledge is not sufficient anymore to reliably predict the result of my work.
If our goal is to continuously widen our understanding over time the accuracy of our prediction would look similar to the following graph:
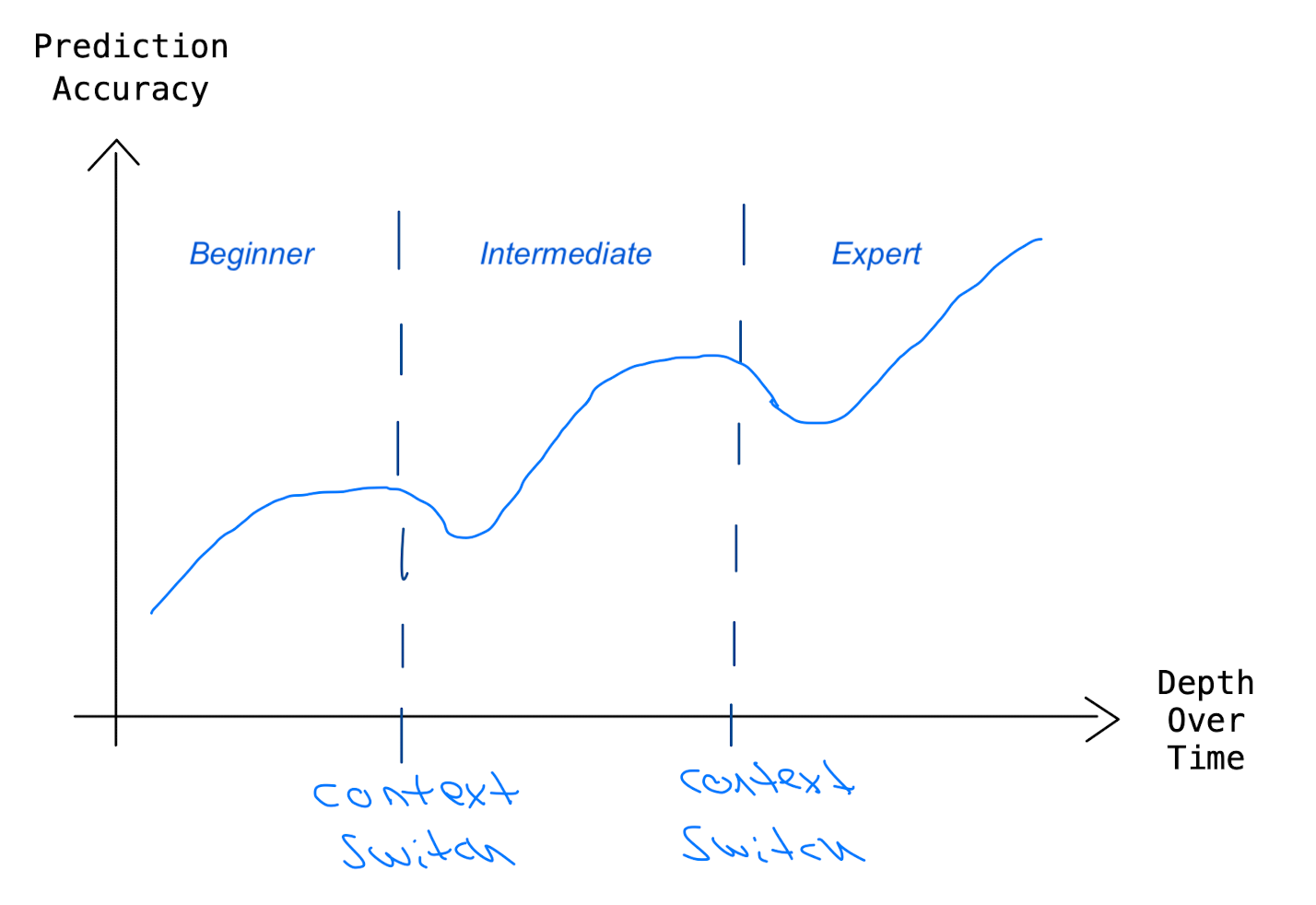
Prediction accuracy over time. Our understanding grows until we hit a plateau. To overcome this, we need to switch the context and go deeper into the subject. This might require extending our mental model or create a new one, which will, in the beginning, cause the accuracy of our predictions to decrease, but once the improved model gets more accurate our overall understanding is becoming wider.
To avoid any gaps, why don’t we learn everything there is about computers? Because we can’t. Grey matter memory is limited. We would never get past all there is to know about hardware before we could even start figuring out how to program something.
That is true for almost everything else. Reality is by far too complex for the human brain to absorb completely. Instead, the brain creates a simplified inner model of the outer world that we use to reason about reality. Models help us to reduce complexity so we can spend our “brain power” on other things. The more accurate our models are, the fewer unexpected events we encounter in our daily life.
Mental models can go far and explain complex processes. Take, for example, the model of “supply and demand” 1, which in simple terms describes how the cost of goods changes over time. More demand with the same supply will increase the price; more supply with less or the same demand decreases the price. This mental model has become so natural to us that talking about it seems trivial, but if I wanted to describe the economics of, let’s say, hardware chips going from research to production to sales, I would need to dive into far more complex processes than mere supply and demand - yet the model is good enough to predict many use cases.
The first takeaway is the we use mental models for all of our thinking.
Unfortunately, models can be inaccurate or wrong. If we learn something new, our model is likely to be incorrect. That is fine as long as we continuously improve the model. The problem is that often we are not aware that we are using a model, even less so a wrong one. Having an inner image is so intrinsic that we don’t realize that this image exists and that it might be wrong.
The second takeaway is that often we are not aware that we use models at all, and worse, that we use wrong models.
Mental models are a “power” tool for efficient learning
A mental model is a tool that enhances our ability to think. As a physical tool enhances the human body’s abilities (e.g. a bicycle amplifies the ability of my legs), mental tools extend brainpower.
What makes a good mental model? It is concise and ideally elegant so that it significantly simplifies the outer world without losing accuracy. The simpler the model, the easier it is for us to absorb it and make it our own.
The model enables us to make predictions. If I can simplify a model while the accuracy of my predictions stays the same, the simpler model is better.
But finding a good model is only the first step. When moving through the stages from beginner to expert, the changing purpose and context will make the best model inaccurate (“All models are wrong, but some are useful” 2). What matters more than the model itself is the ability to improve any model.
Taking an existing good mental model alone won’t be sufficient. We can’t just “copy-and-paste” the image into our brain and hope to gain understanding immediately. We still have to find meaning and have to “make it our own” (what I mean by that exactly is subject to another post). I believe improving the model requires deliberate practice and that having an accurate model can make learning vastly more efficient.
How would such a “practice” look like? The steps are something like the following:
- Define. Be aware that you are using a model and make it visible. That can happen through writing, drawing diagrams or teaching others. You have to express the model so you can actively measure and alter it.
- Test. Find out where your model is wrong or not detailed enough. Do you encounter behaviour that you can’t explain? Has something unexpected happened? Those are the places that need work.
- Improve. Increase the accuracy of the model. You have multiple options for doing that, depending on experience (are you a beginner or expert?), availability of resources, how good the model is - more about this below.
- Simplify or go deeper. Now that your model is primarily accurate, try to simplify it as much as possible. You can significantly increase leverage and deepen your understanding. Can you find a more elegant explanation? What parts of your model are essential, which are superfluous? If you have reached a point where you can’t make more gains, it is time to widen or go deeper. Switch the context.
How to learn efficiently and with confidence
With this in mind, we can answer the questions from above and solve the dilemma of how to best make use of the little we have available for learning.
If your model is mostly off, copy-and-paste answers from the internet will do little to improve understanding and likely cause more problems along the way. Instead, it is time to sit down and do step 2) from above: express your model and make it visible. Then learn the fundamentals (grab a book, watch a video, do an online course) and improve your model until you get to a stage where you can broadly explain behaviour and make accurate predictions.
If you have done the above but still not advanced much in your understanding, the next step is to get practical experience. Most likely, you need both: theory and practice. During your phase of gathering theoretical knowledge, you build your model. During practice, you test it with real-life situations.
If your model seems about right but has minor gaps, then look for quick answers. You will have a map where you can place the answer and are able to tweak your model.
If you feel you have hit a plateau and don’t advance in your understanding, while others seem to have a deeper grasp of things, you need to change the context of your challenge and go deeper. You likely need to create a new, more sophisticated model or come up with several related ones. Think like a scientist. Observe reality, make assumptions (which means formulate a model) and then run experiments to prove or disprove your model. Rinse and repeat.
If your model seems accurate, but feel that you are generally slow and need to look up things often, then, and only then, is it time to memorize knowledge. This is the right time to, for example, learn the details of your Git CLI. Those commands that you keep forgetting. This requires practice. You may even use techniques like spaced repition with flash-cards (which can be helpful in any stage to deepen your internal models).
Mental models are overlooked in software engineering
In software engineering, we lack good mental models. I see the reason for that in the fact that programming is an inherently practical exercise. Feedback loops are usually short - this is what makes programming such a satisfying experience. However, it can lead to a “just try things out until it works”-mentality without having gained a deeper understanding of how things work under the hood.
Also, as mentioned before, there is so much to learn that we simply don’t have the time to look deeper. So we skip on understanding the fundamentals. But this behaviour is short-sighted because, in the long-term, we become much faster and productive once we have built a solid foundation of our knowledge.
The final takeaway is I’m convinced that having crisp mental models is by far the most significant leverage for becoming an efficient learner (and knowledge worker/software engineer). It lets you know where the gaps in your understanding are and what you need to do next. You can see what is essential and what is not. You can look beyond details and see the big picture, relieving you from the need to “cram” knowledge and rely on short-term memory.
For this reason, I created engineeringknowledge.blog with the following two goals in mind:
- describe mental models about selected subjects in software engineering (and other relevant areas)
- and, more importantly, explore and investigate how to develop and improve mental models in general
I consider the second goal more valuable than the first (because knowing the model alone won’t get you far, but if you can develop and improve your own models, you don’t necessarily need an external model - though a good starting point can undoubtedly accelerate learning). Because of that, even though I mostly talk about mental models that occur in software engineering (because that is my day job), I do hope that anyone will benefit from this series.
Please subscribe if you want to keep up-to-date - or reach out if you’d like to share your thoughts.
Photo by Daniel McCullough
Betting as Evidence Amplifier
In her book “The biggest bluff” the author Maria Konnikova describes betting as a “corrective for many of the follies of human reason”. This seems contradictory at first as betting is rarely considered a prudent activity. It is, however, important to distinguish betting (in poker) from gambling. A game like roulette, for example, is based purely on luck. Poker, on the other hand, is a complex game that requires a mix of skills to be successful. Luck plays a role here as well, but as every amateur player who participates in a tournament can confirm, in the long run, the most experienced and skilled players win.
Leaving aside the question of whether betting is a “virtuous” endeavour or not, the point is that introducing a direct cost into our decision making changes how we evaluate a situation. When we make a decision, we are searching for possibilities and evidence. Are the things we believe actually true? The lower the stakes, the less we are inclined to make an effort to question our beliefs. If the costs are high, and in the case of betting in poker, if being wrong leads to an immediate loss, we are much more motivated to scrutinise our assumptions. “Would you bet your house on it?” changes what we claim to be true.
In other words: betting is an evidence amplifier.
We encounter a similar situation in software engineering. The cost of failure determines the stakes of developing software. Do we build a system for the space shuttle or an image sharing app? Will an error cost lives or cause a minor disturbance of a (freemium) user?
Shipping software into production is a bet. Knowing the stakes is a crucial ingredient when determining how much research, testing and rigour we want to invest. In other words, how much evidence we need to seek out before releasing software to the world. When we overestimate the stakes, we may unnecessarily hinder our velocity by over-thinking or over-engineering our solution instead of relying on a shorter release cycle that will lead to actual evidence that the feature works in production. The opposite, however, can be worse. Miscalculating the stakes can lead to underestimating the risk of how much damage shipping a faulty component can cause.
The search-inference framework of thinking
The half-life of a tech-stack
The skills of a software engineer can be split into two groups: those that belong to a tech-stack (A) and those that don’t (B).
Skills in group (A) are directly associated with the ability to use a certain tool, platform or programming language. Skills in group (B), on the other hand, are fuzzy and can’t be defined easily. They are often called soft- or meta-skills.
As a general career strategy, I believe that time invested in honing the skills of group (B) yields a higher return. An engineer needs to have sufficient knowledge of (A) to be useful, but as technology is perpetually changing at an increasing rate, knowledge in that group has a short half-life. In contrast, skills acquired in (B) tend to stay relevant and to grow in value over time. Once you master to communicate well, that skill remains relevant regardless of how the working environment changes.
The most fundamental of all meta-skills is the ability to think (well). As engineers and knowledge workers spend most of their time thinking, doing that as efficient as possible is undoubtedly beneficial. It is a skill that is highly transferable and maximizing it will make everything else better.
Thinking is search and inference
But what does it mean to think well?
In his book “Thinking and Deciding”1 the author Jonathan Baron answers that question by defining a framework that is very much in the wheelhouse of any developer. It is called the search-inference-framework.
We can summarize the framework in the following diagram:
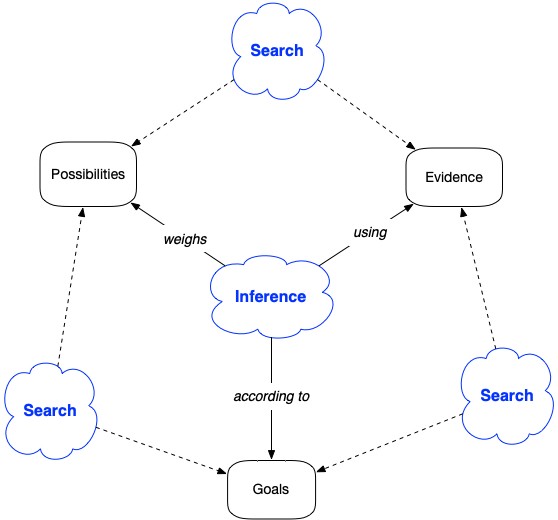
We think when we need to resolve doubts or make a decision about what to do or not to do. We base our decisions on what we believe and what goals we have. To form a belief or build an opinion, we think about possibilities and try to find evidence to support our judgement. We search for answers. This search happens within ourselves (our memories or ideas) or outside (other people, books and so on).
Then, to make a decision or come to a conclusion we infer from our findings. We do so by considering our goals and weighing the options we have available.
The objects of thinking are:
- Possibilities are potential answers to our question that started the search.
- Goals are criteria by which we evaluate possibilities. The word can be misleading. Usually, a goal is something that is either reached or not. Here, more often, a goal is something that can be gradually achieved on a scale.
- Evidence is any form of belief that helps determine if a possibility achieves a goal or not.
Goals are not fixed and can change with new possibilities or evidence.
Good thinking is often synonymous with rational thinking. Baron defines it the following way:
Rational thinking is thinking that is in our best interest. To think rationally means to think in ways that help us best to achieve our goals.
What is counter-intuitive of this definition is that it does not dictate in any way how to think. When we imagine a rational thinker, we often mean someone who thinks logically and without emotions. This is not necessarily rational. If being emotional or illogical brings someone closer to their goal, then that kind of thinking is rational.
Better thinking
With the framework and the definition of rational thinking at hand, we can now answer the question of how to think better. There are two ways:
- improve search
- improve inference
so that we can reach our goals more efficiently.
There are many ways to get better at either search or inference. Proponents of rational thinking discuss mainly overcoming biases and our struggle to inherently grasp probabilities. But doing certain activities alone will already have a positive impact. For example, writing is a full work-out of the search-inference framework. It starts with a goal (or multiple goals) to explore a subject. Interesting writing requires an extensive search for possibilities that have not been conveyed before. To be convincing, an author has to discuss evidence to form a compelling argument.
Freewriting and how to generate ideas bottom-up
One apparent difference between human and artificial intelligence is that an algorithm needs to be fed with adequate data to be able to do something useful. In contrast, the human brain can be quite happy without external input. Giving the mind nothing to work on or confronting it with nonsensical material can stimulate fresh thinking.
This is what an exercise called “freewriting”1 takes advantage of. I find it one of the most effective tools to generate new ideas. The rules are simple: during a limited time (usually 10-20 mins) write about a subject without ever stopping to move your hand (or to type on your keyboard). The key is to never stop writing. When you are out of things to say, instead of interrupting the writing flow by searching your mind for new ideas, jot down nonsensical words (for example, repeat the last word on the page multiple times) or filler phrases. I like to literally translate my mind onto paper and often use sentences like “I don’t know what to say” or “what else am I thinking here” and so on. As long as you keep putting words on paper, it does not matter what they are or if what you write makes any sense at all.
When you do this, something happens.
The brain is a thought producing machine that continuously spits out opinions, worries, ideas, memories and so on. When you challenge your mind with useless repetition and boredom, it will jump out the rut to something else. Quite often, that leads to uncovering new places or hidden corners.
Being able to come up with a fresh set of ideas whenever stuck is tremendously valuable. There is something about this “writing flow” that is not available to other techniques.
Another advantage is that freewriting reliably delivers a sense of accomplishment. As there are almost no rules (just keep going), it is not difficult to reach the writing goal. What is required is a concentrated effort to keep the mind on paper. That is in some respect, similar to what happens during meditation but simpler to execute. The challenge of meditation is not to get distracted and keep the mind aware of what is happening. In freewriting, distractions are welcome, and all we have to do is to follow them with our pen or keyboard. I find that a couple of intense writing sessions can clear up the mind in a similarly satisfying way as meditation can.
Because leaving the path is allowed and encouraged, the likelihood to encounter something new is high - an idea, direction or novel connection between existing ideas. Freewriting helps to enrich our internal map by adding further details to it. Clarity comes from bringing previously unrelated strain of thoughts into alignment.
This “connection making” happens automatically. What we need to do is to “feed” our mind with explorations of concepts, thoughts and mental images and then let it do its work.
Another way to describe what is going on is to developing ideas bottom-up versus top-down. Classical brainstorming starts top-down. We have a question or subject and try to find as many related ideas as possible. A freewriting session initially starts top-down. But then we allow the mind to digress and explore new directions that might not have anything to do with the original question. We then move into a bottom-up approach where ideas emerge through making novel connections. Bottom-up requires less effort as it is more natural to how we think and our brain functions.
I just scratched the surface of this fascinating subject of creativity and human versus artificial intelligence. More to come soon.