
Software engineering is a rapidly evolving industry, putting developers in a perpetual state of having to learn new things while doing their actual job. This is a daunting task, not only because a full-time job leaves little room for training and catching up on the latest changes in tech, but also for the reason that it is becoming increasingly more difficult to decide what and how to learn.
For example, when faced with an engineering problem, the following questions may pop up in a developer’s mind:
- Should I search the internet for a quick answer, hoping to find a copy-and-pasteable solution to my problem? This may or may not work. Often it leads to fruitless attempts and wasted hours.
- Or should I better take out that textbook and try to understand the fundamental ideas? But books are long - where do I start? Maybe a shorter video is a better use of my time?
- Or is it time to get more practical experience instead of indulging in theory and pick up a tutorial or work on a proof-of-concept?
- Why do I seem to have hit a plateau of my understanding and what is required for me to move ahead?
- Why do others appear to grasps things faster while I struggle to get my head around this problem?
As we can all testify, the issue is not that there isn’t enough information to solve a problem. It is the opposite: how can I make sure I invest time in the right activity to learn as efficiently as possible?
I believe there is an answer to all those questions and that it is possible to be confident about what and how to learn. The answer can be found by paying close attention to how we learn.
What does it mean to understand something? Understanding is related to knowledge. The deeper my understanding goes, the more “complete” my knowledge. Gaps in knowledge, on the other hand, are causing a lack of understanding. So when is my understanding “complete”?
I offer the following definition:
My understanding is complete if my knowledge about something is sufficient enough so that I can reliably predict future behaviour.
The ability to reliably predict the behaviour of the thing or process I’m interested in determines my level of understanding. The fewer surprises I encounter, the more I can explain behaviour, the deeper my understanding.
However, all this depends on the purpose of what I’m doing and how deep I need to look into something.
For example, I don’t need to understand how bits are moved on a chip to program a website that runs on a standard server. Knowing about hardware would not increase my ability to predict the behaviour of my code. However, move away from a traditional operating system to specialized hardware, and the situation changes. Now my knowledge is not sufficient anymore to reliably predict the result of my work.
If our goal is to continuously widen our understanding over time the accuracy of our prediction would look similar to the following graph:
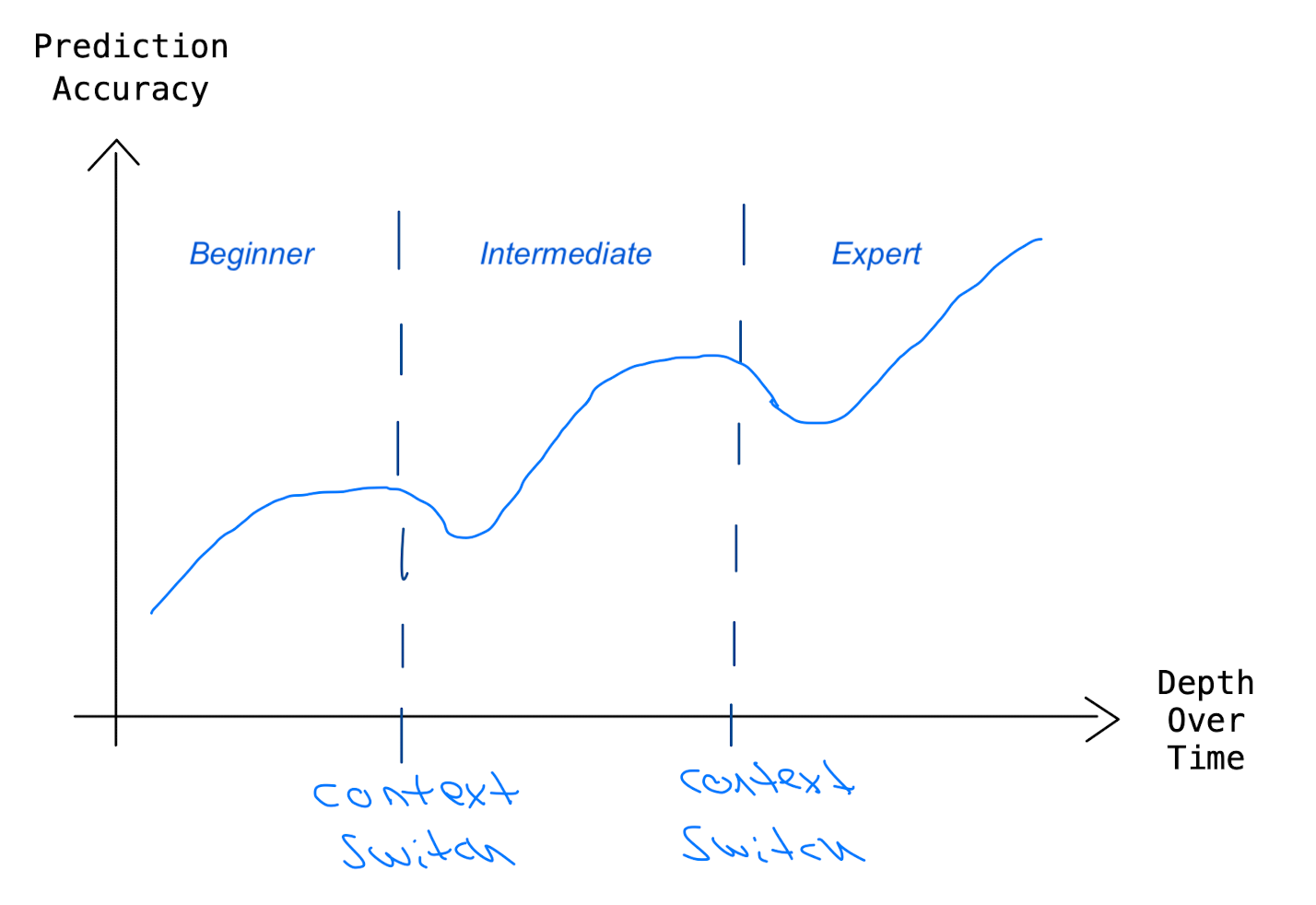
Prediction accuracy over time. Our understanding grows until we hit a plateau. To overcome this, we need to switch the context and go deeper into the subject. This might require extending our mental model or create a new one, which will, in the beginning, cause the accuracy of our predictions to decrease, but once the improved model gets more accurate our overall understanding is becoming wider.
To avoid any gaps, why don’t we learn everything there is about computers? Because we can’t. Grey matter memory is limited. We would never get past all there is to know about hardware before we could even start figuring out how to program something.
That is true for almost everything else. Reality is by far too complex for the human brain to absorb completely. Instead, the brain creates a simplified inner model of the outer world that we use to reason about reality. Models help us to reduce complexity so we can spend our “brain power” on other things. The more accurate our models are, the fewer unexpected events we encounter in our daily life.
Mental models can go far and explain complex processes. Take, for example, the model of “supply and demand” 1, which in simple terms describes how the cost of goods changes over time. More demand with the same supply will increase the price; more supply with less or the same demand decreases the price. This mental model has become so natural to us that talking about it seems trivial, but if I wanted to describe the economics of, let’s say, hardware chips going from research to production to sales, I would need to dive into far more complex processes than mere supply and demand - yet the model is good enough to predict many use cases.
The first takeaway is the we use mental models for all of our thinking.
Unfortunately, models can be inaccurate or wrong. If we learn something new, our model is likely to be incorrect. That is fine as long as we continuously improve the model. The problem is that often we are not aware that we are using a model, even less so a wrong one. Having an inner image is so intrinsic that we don’t realize that this image exists and that it might be wrong.
The second takeaway is that often we are not aware that we use models at all, and worse, that we use wrong models.
Mental models are a “power” tool for efficient learning
A mental model is a tool that enhances our ability to think. As a physical tool enhances the human body’s abilities (e.g. a bicycle amplifies the ability of my legs), mental tools extend brainpower.
What makes a good mental model? It is concise and ideally elegant so that it significantly simplifies the outer world without losing accuracy. The simpler the model, the easier it is for us to absorb it and make it our own.
The model enables us to make predictions. If I can simplify a model while the accuracy of my predictions stays the same, the simpler model is better.
But finding a good model is only the first step. When moving through the stages from beginner to expert, the changing purpose and context will make the best model inaccurate (“All models are wrong, but some are useful” 2). What matters more than the model itself is the ability to improve any model.
Taking an existing good mental model alone won’t be sufficient. We can’t just “copy-and-paste” the image into our brain and hope to gain understanding immediately. We still have to find meaning and have to “make it our own” (what I mean by that exactly is subject to another post). I believe improving the model requires deliberate practice and that having an accurate model can make learning vastly more efficient.
How would such a “practice” look like? The steps are something like the following:
- Define. Be aware that you are using a model and make it visible. That can happen through writing, drawing diagrams or teaching others. You have to express the model so you can actively measure and alter it.
- Test. Find out where your model is wrong or not detailed enough. Do you encounter behaviour that you can’t explain? Has something unexpected happened? Those are the places that need work.
- Improve. Increase the accuracy of the model. You have multiple options for doing that, depending on experience (are you a beginner or expert?), availability of resources, how good the model is - more about this below.
- Simplify or go deeper. Now that your model is primarily accurate, try to simplify it as much as possible. You can significantly increase leverage and deepen your understanding. Can you find a more elegant explanation? What parts of your model are essential, which are superfluous? If you have reached a point where you can’t make more gains, it is time to widen or go deeper. Switch the context.
How to learn efficiently and with confidence
With this in mind, we can answer the questions from above and solve the dilemma of how to best make use of the little we have available for learning.
If your model is mostly off, copy-and-paste answers from the internet will do little to improve understanding and likely cause more problems along the way. Instead, it is time to sit down and do step 2) from above: express your model and make it visible. Then learn the fundamentals (grab a book, watch a video, do an online course) and improve your model until you get to a stage where you can broadly explain behaviour and make accurate predictions.
If you have done the above but still not advanced much in your understanding, the next step is to get practical experience. Most likely, you need both: theory and practice. During your phase of gathering theoretical knowledge, you build your model. During practice, you test it with real-life situations.
If your model seems about right but has minor gaps, then look for quick answers. You will have a map where you can place the answer and are able to tweak your model.
If you feel you have hit a plateau and don’t advance in your understanding, while others seem to have a deeper grasp of things, you need to change the context of your challenge and go deeper. You likely need to create a new, more sophisticated model or come up with several related ones. Think like a scientist. Observe reality, make assumptions (which means formulate a model) and then run experiments to prove or disprove your model. Rinse and repeat.
If your model seems accurate, but feel that you are generally slow and need to look up things often, then, and only then, is it time to memorize knowledge. This is the right time to, for example, learn the details of your Git CLI. Those commands that you keep forgetting. This requires practice. You may even use techniques like spaced repition with flash-cards (which can be helpful in any stage to deepen your internal models).
Mental models are overlooked in software engineering
In software engineering, we lack good mental models. I see the reason for that in the fact that programming is an inherently practical exercise. Feedback loops are usually short - this is what makes programming such a satisfying experience. However, it can lead to a “just try things out until it works”-mentality without having gained a deeper understanding of how things work under the hood.
Also, as mentioned before, there is so much to learn that we simply don’t have the time to look deeper. So we skip on understanding the fundamentals. But this behaviour is short-sighted because, in the long-term, we become much faster and productive once we have built a solid foundation of our knowledge.
The final takeaway is I’m convinced that having crisp mental models is by far the most significant leverage for becoming an efficient learner (and knowledge worker/software engineer). It lets you know where the gaps in your understanding are and what you need to do next. You can see what is essential and what is not. You can look beyond details and see the big picture, relieving you from the need to “cram” knowledge and rely on short-term memory.
For this reason, I created engineeringknowledge.blog with the following two goals in mind:
- describe mental models about selected subjects in software engineering (and other relevant areas)
- and, more importantly, explore and investigate how to develop and improve mental models in general
I consider the second goal more valuable than the first (because knowing the model alone won’t get you far, but if you can develop and improve your own models, you don’t necessarily need an external model - though a good starting point can undoubtedly accelerate learning). Because of that, even though I mostly talk about mental models that occur in software engineering (because that is my day job), I do hope that anyone will benefit from this series.
Please subscribe if you want to keep up-to-date - or reach out if you’d like to share your thoughts.
Photo by Daniel McCullough